
目录
0 前言
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——作业笔记HW5的补充内容2。
如果你还没获取到LLM API,请查看我的另一篇笔记:
HW1~2:LLM API获取步骤及LLM API使用演示:环境配置与多轮对话演示-CSDN博客
完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
在文章HW5-补充1:深入理解 Beam Search——原理, 示例与代码实现-CSDN博客中我们探讨了 Beam Search 和 Greedy Search,现在来聊聊
model.generate()中常见的三个参数: top-k, top-p 和 temperature。
1 采样方法概述
在生成文本时,模型为每个可能的下一个词汇分配一个概率分布,选择下一个词汇的策略直接决定了输出的质量和多样性。以下是几种常见的选择方法:
- Greedy Search(贪心搜索): 每次选择概率最高的词汇。
- Beam Search(束搜索): 保留多个候选序列,平衡生成质量和多样性。
- Top-K 采样: 限制候选词汇数量。
- Top-P 采样(Nucleus Sampling): 根据累积概率选择候选词汇,动态调整词汇集。
为了直观叙述,假设我们当前的概率分布为:
| 词汇 | 概率 |
|---|---|
| A | 0.4 |
| B | 0.3 |
| C | 0.2 |
| D | 0.05 |
| 0.05 |
2 Top-K采样详解
2.1 工作原理
Top-K 采样是一种通过限制候选词汇数量来增加生成文本多样性的方法。在每一步生成过程中,模型只考虑概率最高(Top)的 K 个词汇,然后从这 K 个词汇中根据概率进行采样(K=1 就是贪心搜索)。
步骤:
- 获取概率分布: 模型为每个可能的下一个词汇生成一个概率分布。
- 筛选 Top-K: 选择概率最高的 K 个词汇,忽略其余词汇。
- 重新归一化: 将筛选后的 K 个词汇的概率重新归一化,使其总和为 1。
- 采样: 根据重新归一化后的概率分布,从 Top-K 词汇中随机采样一个词汇作为下一个生成的词。
2.2 数学表述

2.3 代码示例
假设 K=3。
- import numpy as np
-
- # 概率分布
- probs = np.array([0.4, 0.3, 0.2, 0.05, 0.05])
- words = ['A', 'B', 'C', 'D', '
' ] -
- # 设置 Top-K
- K = 3
-
- # 获取概率最高的 K 个词汇索引
- top_indices = np.argsort(probs)[-K:]
-
- # 保留这些 K 个词汇及其概率
- top_k_probs = np.zeros_like(probs)
- top_k_probs[top_indices] = probs[top_indices]
-
- # 归一化保留的 K 个词汇的概率
- top_k_probs = top_k_probs / np.sum(top_k_probs)
-
- # 打印 Top-K 采样的结果
- print("Top-K 采样选择的词汇和对应的概率:")
- for i in top_indices:
- print(f"{words[i]}: {top_k_probs[i]:.2f}")
输出:
Top-K 采样选择的词汇和对应的概率:
C: 0.22
B: 0.33
A: 0.44
3 Top-P采样详解
3.1 工作原理
Top-P 采样(又称 Nucleus Sampling)是一种动态选择候选词汇的方法。与 Top-K 采样不同,Top-P 采样不是固定选择 K 个词汇,而是选择一组累计概率达到 P 的词汇集合(即从高到低加起来的概率)。这意味着 Top-P 采样可以根据当前的概率分布动态调整候选词汇的数量,从而更好地平衡生成的多样性和质量。
步骤:
- 获取概率分布: 模型为每个可能的下一个词汇生成一个概率分布。
- 排序概率: 将词汇按照概率从高到低排序。
- 累积概率: 计算累积概率,直到达到预设的阈值 P。
- 筛选 Top-P: 选择累积概率达到 P 的最小词汇集合。
- 重新归一化: 将筛选后的词汇概率重新归一化。
- 采样: 根据重新归一化后的概率分布,从 Top-P 词汇中随机采样一个词汇作为下一个生成的词。
3.2 数学表述

3.3 代码示例
假设 P=0.6。
- import numpy as np
-
- # 概率分布
- probs = np.array([0.4, 0.3, 0.2, 0.05, 0.05])
- words = ['A', 'B', 'C', 'D', '
' ] -
- # 设置 Top-P
- P = 0.6
-
- # 对概率进行排序
- sorted_indices = np.argsort(probs)[::-1] # 从大到小排序
- sorted_probs = probs[sorted_indices]
-
- # 累积概率
- cumulative_probs = np.cumsum(sorted_probs)
-
- # 找到累积概率大于等于 P 的索引
- cutoff_index = np.where(cumulative_probs >= P)[0][0]
-
- # 保留累积概率达到 P 的词汇及其概率
- top_p_probs = np.zeros_like(probs)
- top_p_probs[sorted_indices[:cutoff_index + 1]] = sorted_probs[:cutoff_index + 1]
-
- # 归一化保留的词汇的概率
- top_p_probs = top_p_probs / np.sum(top_p_probs)
-
- # 打印 Top-P 采样的结果
- print("\nTop-P 采样选择的词汇和对应的概率:")
- for i in np.where(top_p_probs > 0)[0]:
- print(f"{words[i]}: {top_p_probs[i]:.2f}")
- Top-P 采样选择的词汇和对应的概率:
- A: 0.57
- B: 0.43
4 Temperature的作用
Temperature(温度) 是控制生成文本随机性的参数。
4.1 工作原理
在进行采样前,模型实际上会对概率分布应用温度调整:

4.2 例子
举个例子,P(A)=0.16,P(B)=0.04。
1)当T约等于0时:
选择A的概率为:(无限接近于1)
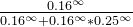
选择B的概率为:(无限接近于0)

2)当T大于1,等于2时:
选择A的概率为2/3;
选择B的概率为1/3。
如此,当T大于1时,低概率词汇的选择概率便大大增加了。
4.3 代码示例
这里将展示 Temperature 对概率的影响。
- import numpy as np
- import matplotlib.pyplot as plt
-
- # 概率分布
- probs = np.array([0.4, 0.3, 0.2, 0.05, 0.05])
- words = ['A', 'B', 'C', 'D', '
' ] -
- # 设置 Top-K
- K = 5
-
- # 设置不同的 Temperature 值
- temperatures = [0.5, 1.0, 1.5]
-
- # 创建一个图表
- plt.figure(figsize=(10, 6))
-
- # 遍历不同的温度
- for temp in temperatures:
- # 使用 Temperature 调整概率
- adjusted_probs = probs ** (1.0 / temp)
- adjusted_probs = adjusted_probs / np.sum(adjusted_probs) # 归一化
-
- # 打印当前 Temperature 的概率分布
- print(f"\n--- Temperature = {temp} ---")
- for i, prob in enumerate(adjusted_probs):
- print(f"{words[i]}: {prob:.2f}")
-
- # 绘制概率分布图
- plt.plot(words, adjusted_probs, label=f"Temperature = {temp}")
-
- # 绘制原始概率分布的对比
- plt.plot(words, probs, label="Original", linestyle="--", color="black")
-
- # 添加图表信息
- plt.xlabel("Word")
- plt.ylabel("Probability")
- plt.title("Effect of Temperature on Top-K Probability Distribution")
- plt.legend()
-
- # 显示图表
- plt.show()
输出:
- --- Temperature = 0.5 ---
- A: 0.54
- B: 0.31
- C: 0.14
- D: 0.01
: 0.01 -
- --- Temperature = 1.0 ---
- A: 0.40
- B: 0.30
- C: 0.20
- D: 0.05
: 0.05 -
- --- Temperature = 1.5 ---
- A: 0.34
- B: 0.28
- C: 0.21
- D: 0.08
: 0.08
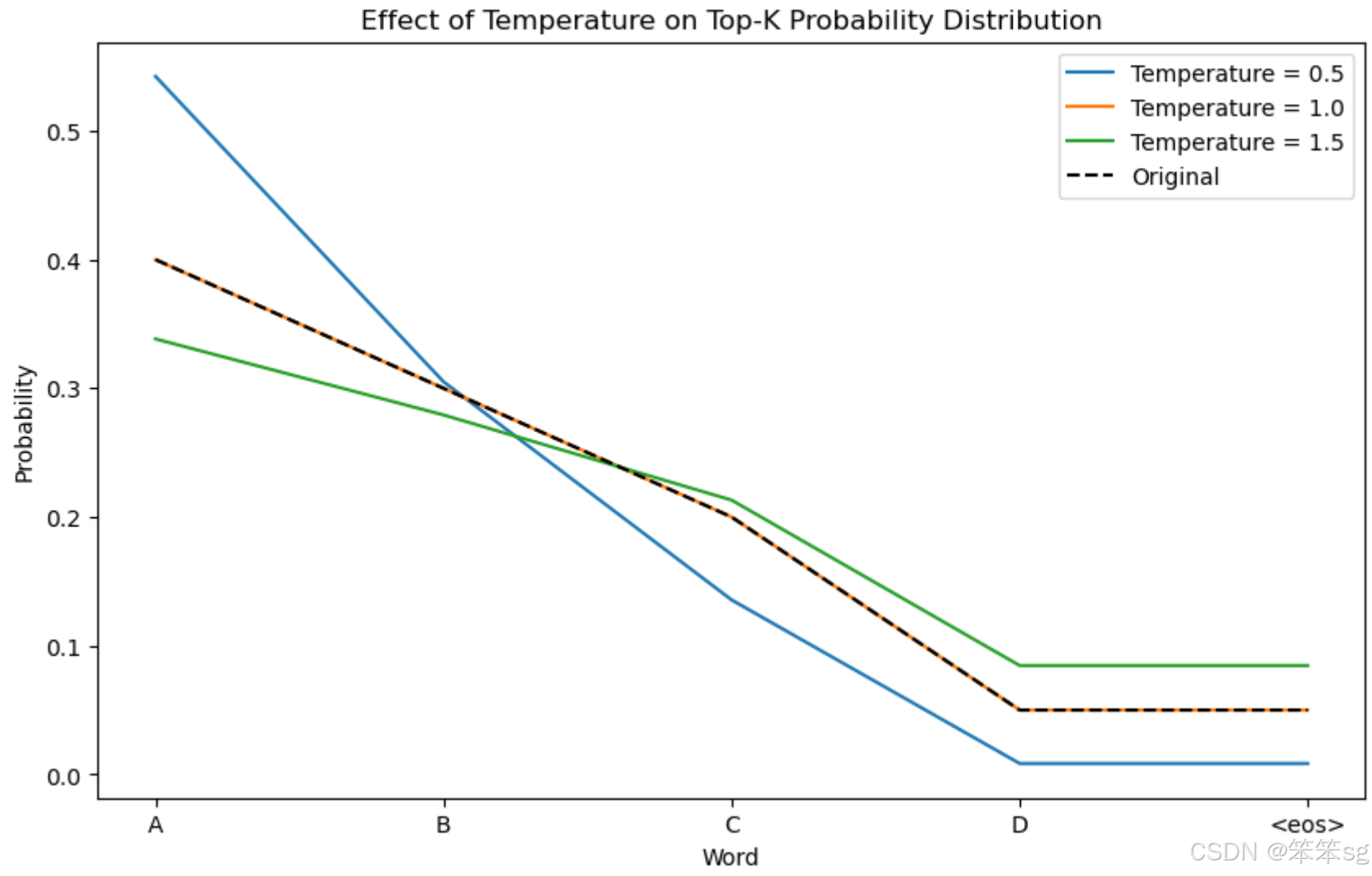
观察图片可以直观看到:
- 当 temperature < 1 时,概率分布变得更加尖锐,高概率词更可能被选择,适用于需要高确定性的任务,如生成技术文档或代码。
- 当 temperature > 1 时,概率分布变得更加平坦,使得低概率词也有更多机会被选中,适用于需要创造性和多样性的任务,如写作或对话生成。
5 在大模型中的应用
5.1 Top-K和Top-P采样是否可以一起使用?
可以,通过同时设置 top_k 和 top_p 参数,模型会首先应用 Top-K 筛选,限制候选词汇数量,然后在这有限的词汇中应用 Top-P 采样,动态调整词汇集合。(K个加起来都没达到P则直接全选,不再重新采样)
使用 Hugging Face Transformers 库的简单示例:
- import warnings
- from transformers import AutoTokenizer, AutoModelForCausalLM
- import torch
-
- # 忽略 FutureWarning 警告
- warnings.filterwarnings("ignore", category=FutureWarning)
-
- # 指定模型
- model_name = "distilgpt2"
-
- # 加载分词器和模型
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- model = AutoModelForCausalLM.from_pretrained(model_name)
-
- # 将模型移动到设备
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- model.to(device)
-
- # 输入文本
- input_text = "Hello GPT"
-
- # 编码输入文本
- inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
- attention_mask = torch.ones_like(inputs).to(device)
-
- # 设置 Top-K 和 Top-P 采样
- top_k = 10
- top_p = 0.5
- temperature = 0.8
-
- # 生成文本,结合 Top-K 和 Top-P 采样
- with torch.no_grad():
- outputs = model.generate(
- inputs,
- attention_mask=attention_mask,
- max_length=50,
- do_sample=True,
- top_k=top_k, # 设置 Top-K
- top_p=top_p, # 设置 Top-P
- temperature=temperature, # 控制生成的随机性
- no_repeat_ngram_size=2, # 防止重复 n-gram
- pad_token_id=tokenizer.eos_token_id
- )
-
- # 解码生成的文本
- generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
- print("结合 Top-K 和 Top-P 采样生成的文本: ")
- print(generated_text)
输出示例:
- 结合 Top-K 和 Top-P 采样生成的文本:
- Hello GPT.
-
- The first time I heard of the G-E-X-1, I was wondering what the future holds for the company. I had no idea what it was. It was a very big company, and it had
参数解释:
top_k=10: 首先限制候选词汇为概率最高的 10 个。top_p=0.5: 在这 10 个词汇中,从高到低,选择累积概率达到 0.5 的词汇归一化后进行采样。temperature=0.8: 控制生成的随机性,较低的温度使模型更倾向于高概率词汇。
5.2 如果我只想使用Top-K或者Top-P应该怎么办?
对于只使用 Top-K:
将 top_p 设置为 1(表示不使用 Top-P 采样)
- outputs = model.generate(
- inputs,
- max_length=50,
- do_sample=True,
- top_k=top_k, # 设置 Top-K
- top_p=1.0, # 不使用 Top-P
- temperature=temperature, # 控制生成的随机性
- no_repeat_ngram_size=2, # 防止重复 n-gram
- eos_token_id=tokenizer.eos_token_id
- )
对于只使用 Top-P:
将 top_k 设置为 0(表示不使用 Top-K 采样)。
- outputs = model.generate(
- inputs,
- max_length=50,
- do_sample=True,
- top_k=0, # 不使用 Top-K
- top_p=top_p, # 设置 Top-P
- temperature=temperature, # 控制生成的随机性
- no_repeat_ngram_size=2, # 防止重复 n-gram
- eos_token_id=tokenizer.eos_token_id
- )
评论记录:
回复评论: