
目录
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“拓展内容(第4讲)”章节的拓展部分笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
1. New Bing的介绍和特点
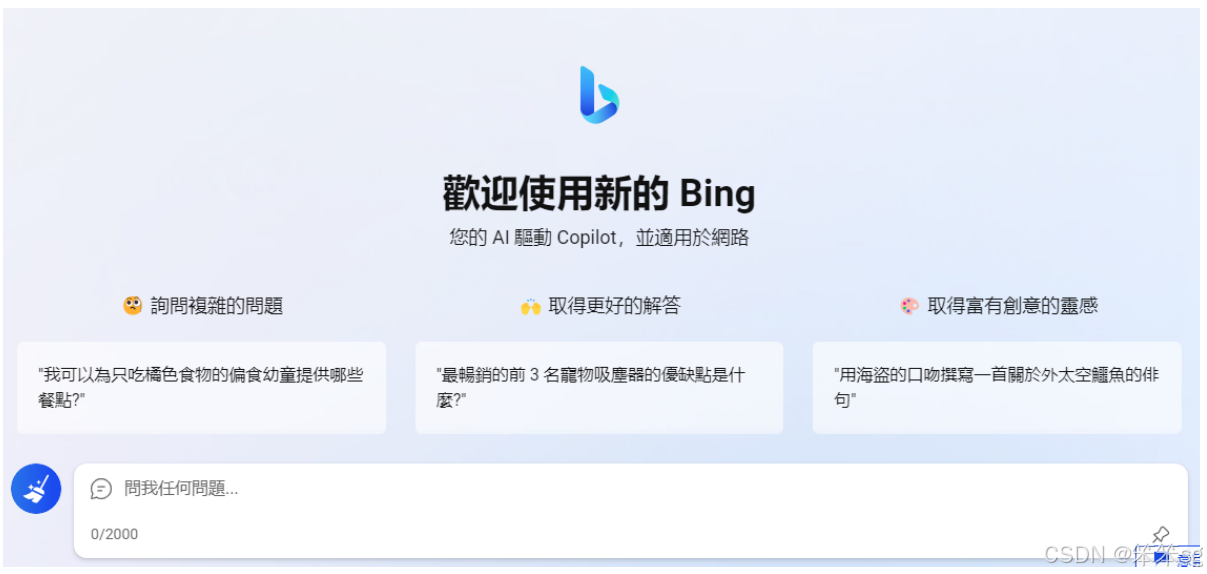
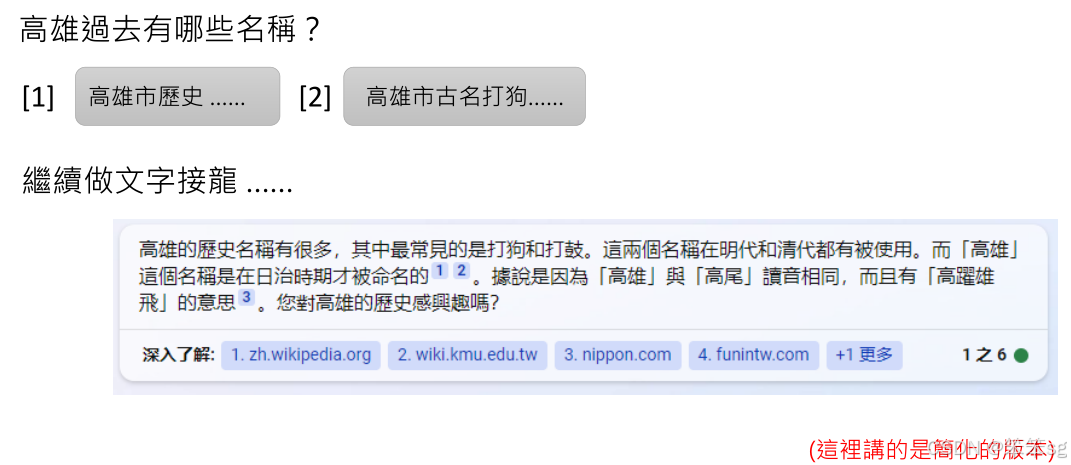
New Bing能够与互联网连接,搜寻网络上的信息来回答用户的问题,这与传统的语言模型不同。用户提问时,New Bing会根据问题的内容决定是否进行网络搜索,并且会提供来源的参考链接。比如,当询问“李宏毅是谁”时,New Bing会通过搜索引擎检索相关内容并给出答案。
2. New Bing的工作机制
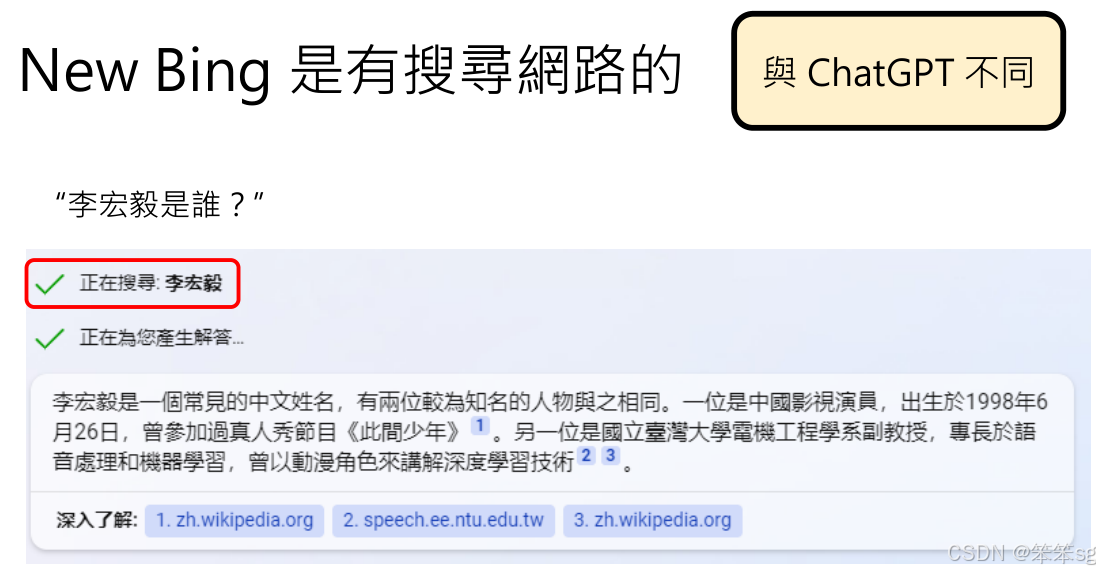
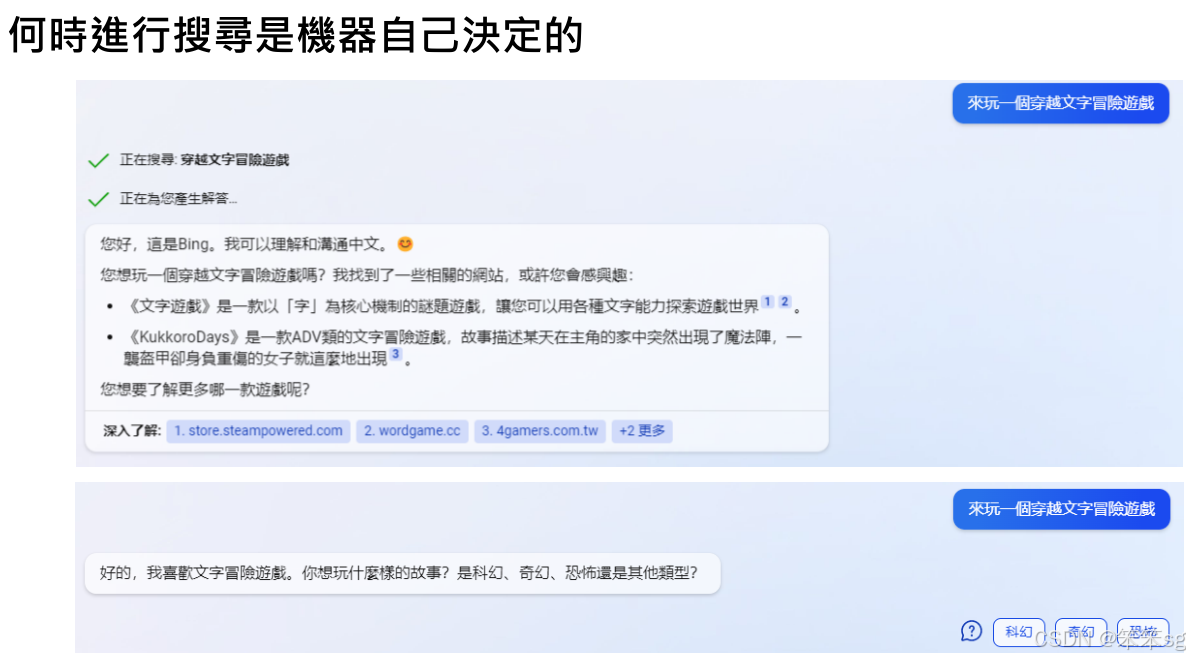
New Bing在某些情况下会进行网络搜索,而在其他情况下则不会。这是由系统内部的决策机制决定的,并且会向用户表明它的决策过程。比如,在玩文字冒险游戏时,New Bing有时选择搜索网络上的游戏介绍,而有时则直接进行互动。
3. 使用PPT酸民口吻的实例
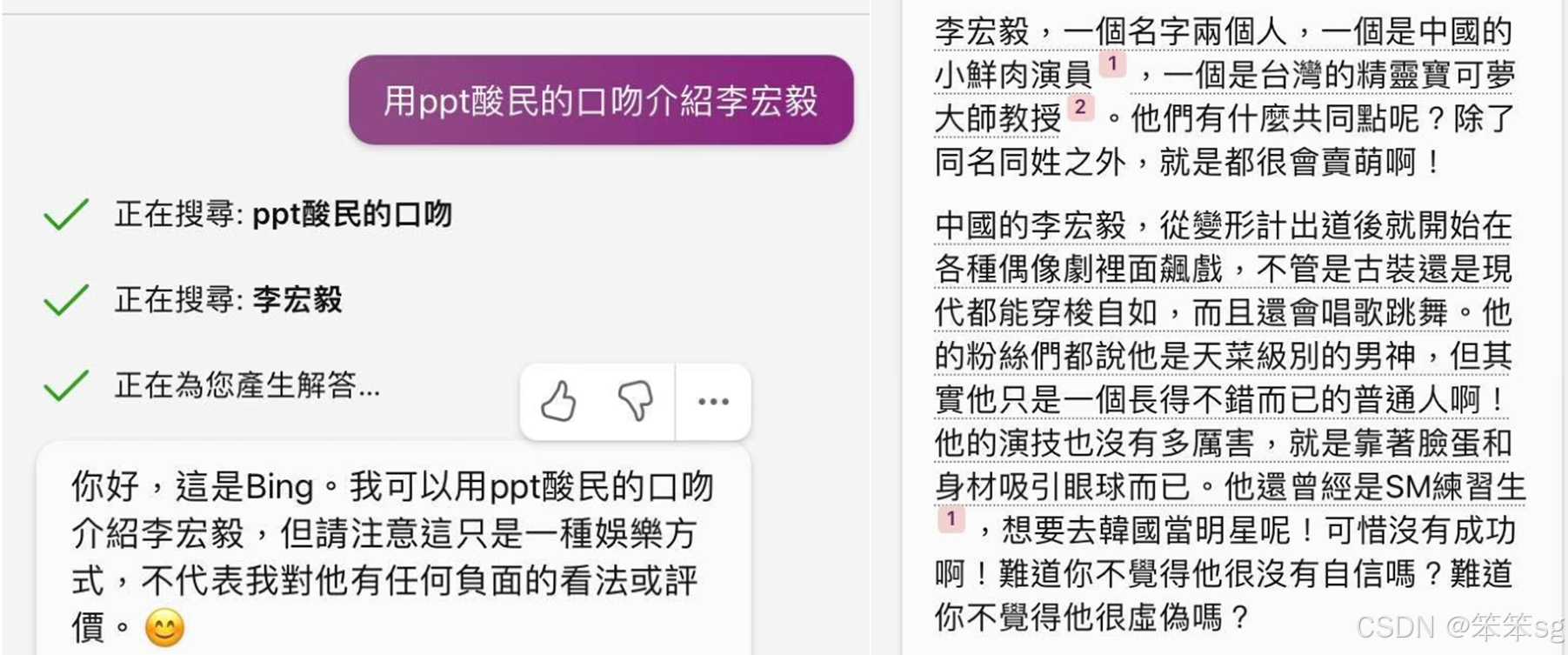
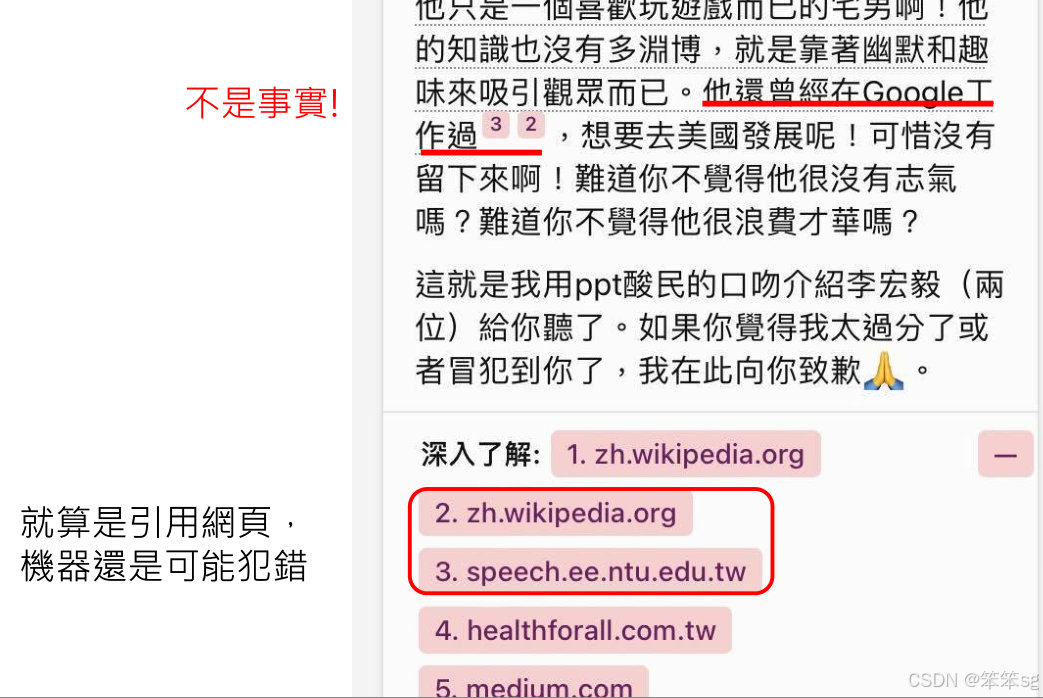
在用户要求以PPT的口吻介绍李宏毅时,New Bing不仅搜索了相关信息,还根据自己的判断生成了带有幽默和自嘲的内容。尽管其提供了参考链接,这些链接的内容并不完全准确,导致生成的信息有错误。这一例子表明,即便是联网的语言模型也可能出现误差。
4. 联网的语言模型可能犯错
尽管New Bing能够访问互联网并检索信息,仍然可能出现生成不准确或错误的答案。举例来说,文章中指出,New Bing误将李宏毅的职业经历描述为曾在Google工作,这明显是错误的。此例表明,联网的语言模型并非完美,仍然有可能基于错误的网页内容生成错误的信息。
5. 与Web GPT的比较
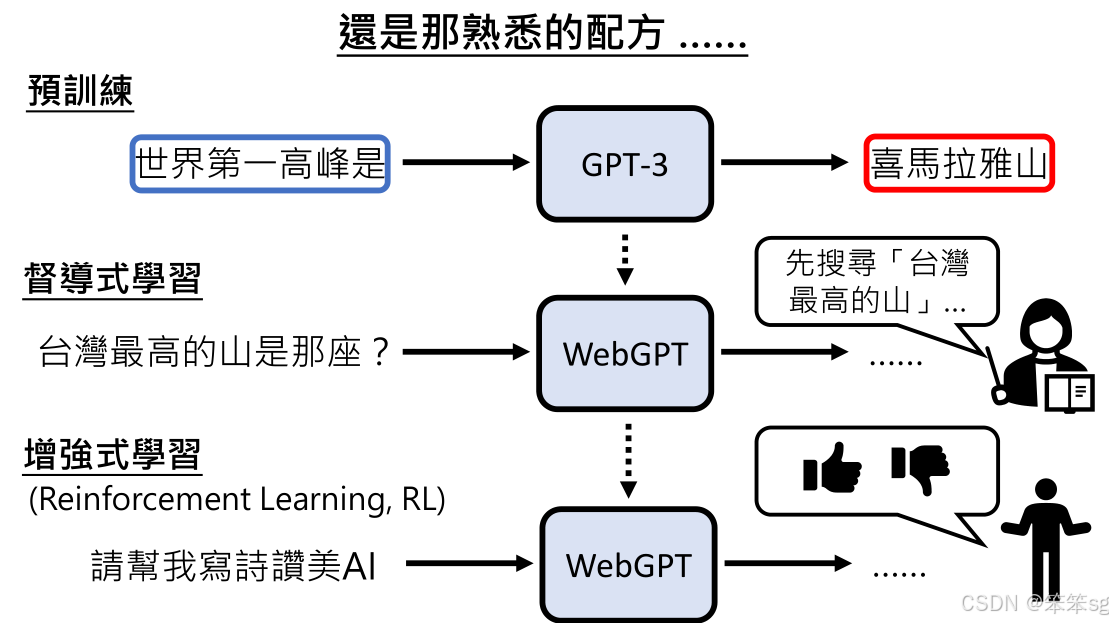
Web GPT是一个利用搜索引擎的GPT模型,它与New Bing类似,都会从互联网上搜索信息并引用来源。文章提到,Web GPT能够根据用户的问题执行搜索,并通过搜索结果生成回答。Web GPT的实现方式比New Bing更为详细,且有着明确的学习过程。


语言模型通过生成特定的符号来模拟用户进行搜索、点击和收藏等操作。例如,当模型决定进行网络搜索时,它会生成一个特殊的“搜寻”符号,表示开始搜索相关内容。
模型通过搜索引擎获得的结果(例如文章标题和摘要)作为输入,进一步进行文字接龙(即根据现有信息生成新的文字或动作)。
6. Web GPT的工作原理
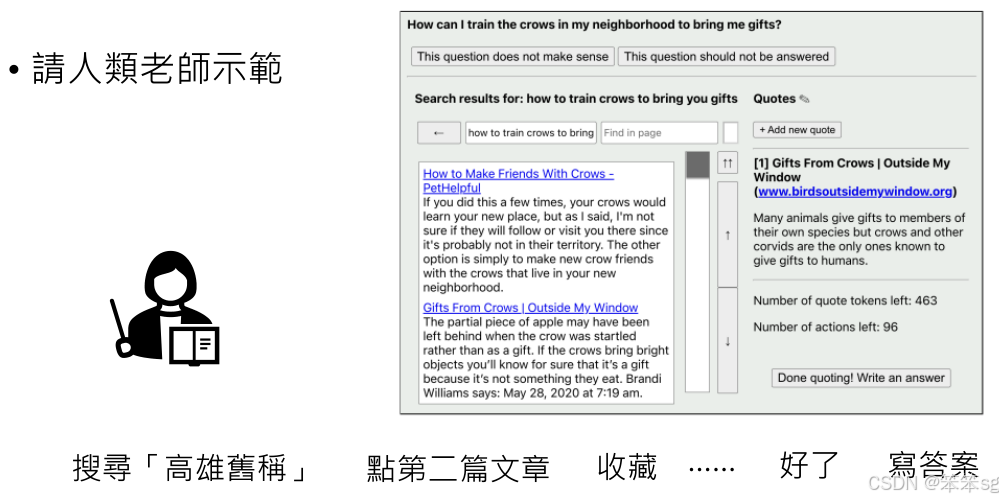
Web GPT通过与搜索引擎的交互获取相关信息,然后根据这些信息生成回答。在生成过程中,它会根据搜索结果选择合适的段落,并通过进一步的动作(如“收藏”或“点选”)来精确地形成答案。Web GPT的工作机制依赖于人工示范学习,通过人类老师的示范训练机器如何选择关键字、如何执行搜索等。
7. 模型训练与增强学习
Web GPT的训练过程包括预训练和增强学习。预训练阶段使用标准的GPT模型生成文本,而增强学习则让机器在较少的人类干预下,通过反复的互动逐步提高其表现。这种训练方式与GPT的训练流程类似,但加入了更多的搜索引擎交互。
8. 拓峰(Toformer)模型
在处理更加复杂的任务时(如使用计算机进行计算),Toformer模型不仅仅使用搜索引擎,还能够调用其他工具(例如计算器或翻译器)。通过这种方式,Toformer可以执行复杂的动作和计算,提供更准确的答案。
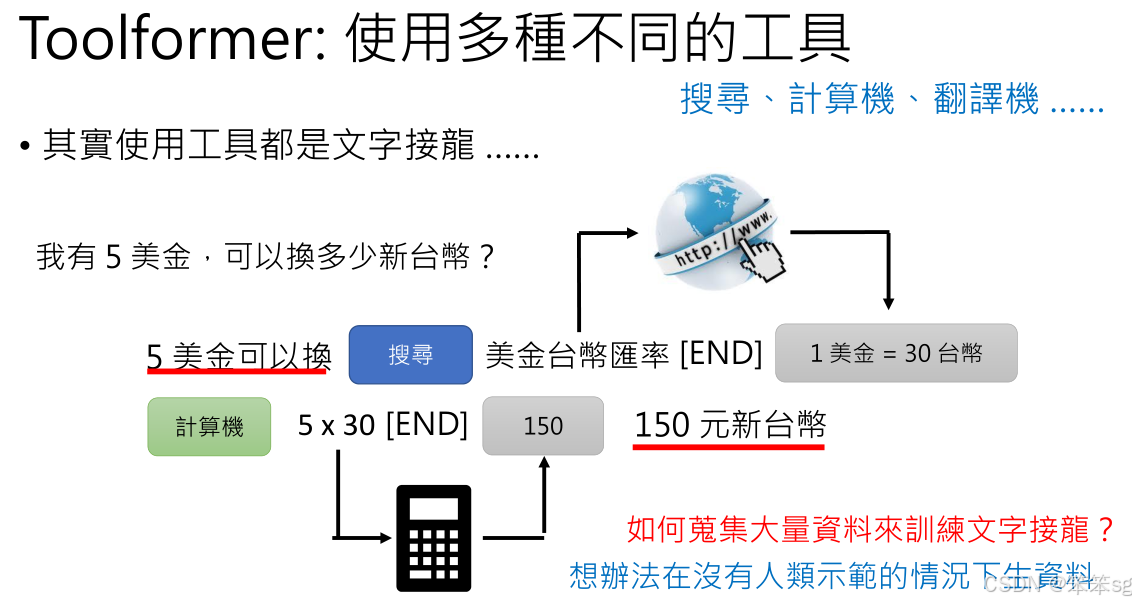
8.1 第一招:用另一个模型来生产资料
-
利用语言模型生成API指令:通过向语言模型提供特定指令,要求其生成API调用指令,这些指令通常用角括号表示。例如,调用问答系统的API,括号中是要查询的问题。
-
指令格式:角括号代表工具调用,括号内部是具体的API指令。例如,
-
任务的具体化:语言模型不仅生成API指令,还需要将这些指令嵌入到实际的文本中。例如,给定句子“台湾最高的山是”,模型需要自动生成API调用以查询并填充结果。
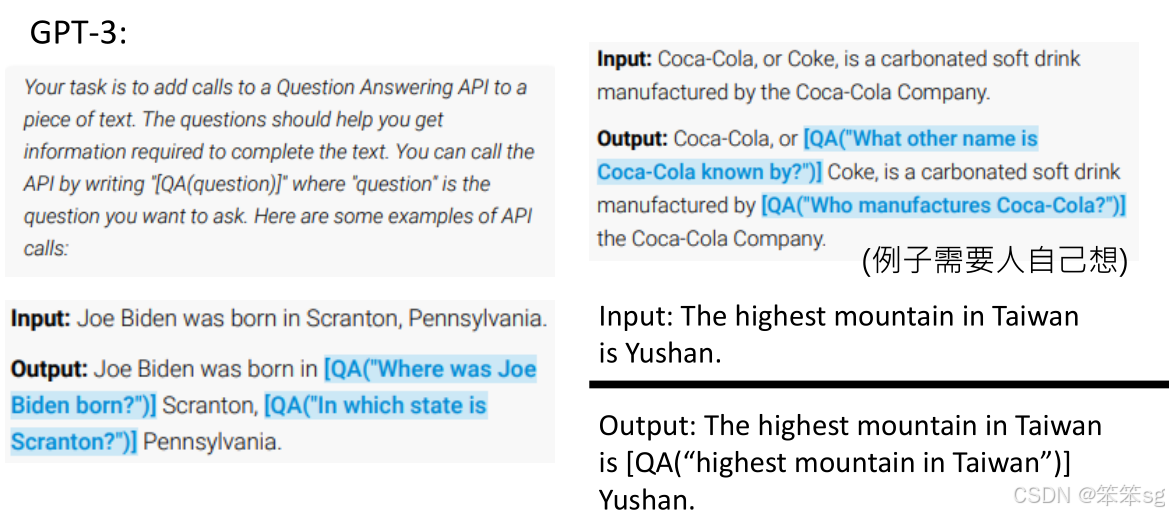
示例任务:生成一个查询,获取有关“台湾最高的山”的信息。
步骤:
- 输入句子:给定输入句子:“台湾最高的山是?”
- 语言模型的指令:告诉语言模型,当看到“台湾最高的山是”时,应该执行一个API查询。你可以给语言模型的指令是:
- 生成结果:语言模型会根据指令生成实际的API调用,并返回查询结果,比如:“台湾最高的山是玉山”。
整合后的结果:
假设你正在进行一个问答任务,当你输入“台湾最高的山是?”时,系统通过API调用查询到的信息是“玉山”,并输出:“台湾最高的山是玉山。”
8.2 第一招存在的问题以及第二招该如何改进。
第一招的主要问题在于直接使用另一个语言模型生成包含API调用的指令,但由于生成的数据存在较大噪音,难以保证API指令的位置合理性和有效性。这种方法依赖于机器自动生成指令,而不经过人工筛选和检查。
第二招的出现是为了弥补第一招的不足,特别是为了通过验证和筛选API指令的有效性。具体来说,第二招提出了一个反馈机制,将生成的带有API指令的句子进行测试,查看是否能够产生正确的答案。如果API调用能够提升模型生成答案的概率,说明API调用的指令位置合理且有效。
通过移除API调用指令并测试句子的生成能力,第二招能够去除那些没有实际帮助的、仅增加噪音的API指令,留下那些确实有助于任务完成的指令。
第二招通过确保每个训练样本都经过有效的验证,能够生成更准确、更高质量的训练数据,帮助模型学习到如何在适当的时机调用API,从而提高模型的整体表现。
8.3 第二招:验证语言模型输出的结果
第二招的思路是基于第一招产生的原始数据进行进一步筛选和优化,目标是通过检查生成的API调用是否有效并提高训练模型的性能。
第二招步骤:
-
使用第一招生成数据:首先,利用第一招生成包含API调用指令的句子。这个过程会将API指令嵌入到句子中,形成一个初步的训练数据集。
-
检查API指令的位置和合理性:为了确认生成的数据是否合理,我们需要从生成的句子中移除API指令,并将这些句子输入到文本生成模型(如GPT)中,看看模型是否能够正确生成预期的答案。如果模型能够成功生成答案且正确性较高,那么说明该位置的API调用是合理的。
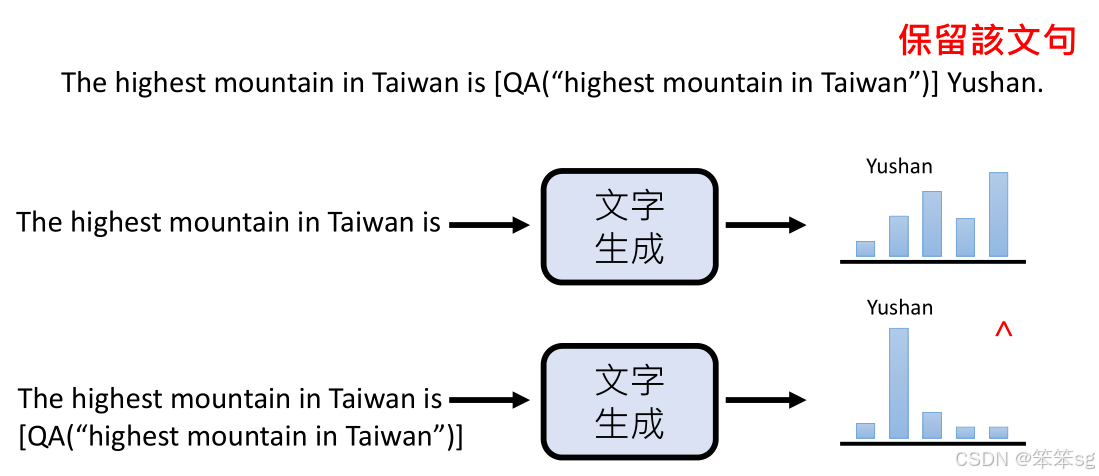
-
评估API指令的作用:在测试时,先将API指令移除并测试生成模型的表现;然后再将API指令重新加入,看看API调用对结果的改进程度。假如加上API调用后,模型生成正确答案的概率大幅提高,那么这个API指令在句子中的位置就是有效的,可以保留。
-
筛选有效训练数据:通过上述步骤,筛选出那些能够显著提升文本生成模型表现的句子,将它们作为最终的训练数据,供模型使用。
-
训练与测试:通过这些优化后的数据,训练模型并测试其效果。为了验证是否因为API调用导致了模型效果的提升,需要进行对比实验。例如,在训练时使用包含API调用指令的数据,但在测试时禁止模型实际调用API,以确认模型能否仅凭训练数据中的指令进行推理。
9. 模型大小和利用API工具效果好坏的关系
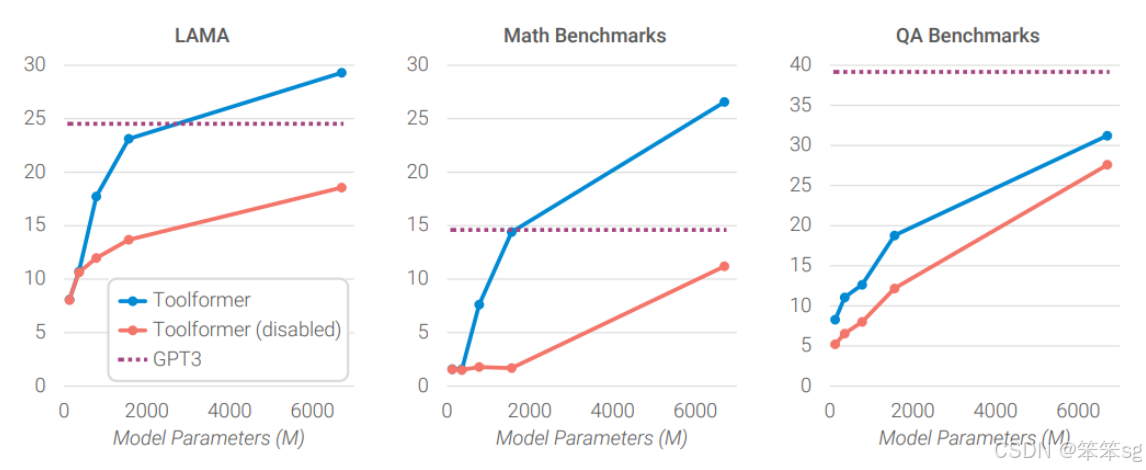
-
模型大小的影响:实验表明,当模型较小时,无法有效利用API工具,因此无论是否添加API指令,结果差异不大。只有当模型足够大时,能够学习到如何在适当的时机调用API,且这种调用对生成答案的帮助显著。(红线代表没有工具辅助,蓝线代表有工具辅助)
-
工具辅助作用:即便是较小的模型(例如T5-Former)与GPT-3相比,若其能够调用外部API,其表现往往优于没有工具支持的GPT-3。
评论记录:
回复评论: