
目录
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“拓展内容(第0~1讲)”章节的拓展部分笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
1 80分钟快速全面了解大型语言模型
1.1 概述
- 在本章节中,李老师通过实际的考试题目测试ChatGPT的回答,发现其在某些陷阱题上表现不佳,尽管整体正确率较高。
- 他还展示了如何利用ChatGPT生成线性代数考题和使用五条体描述内容。
- 此外,课程强调了预训练、监督学习和增强学习在模型训练中的重要性;
- 以及如何通过提供明确指示和示例来提高模型的表现。
1.2 解答数学问题
大型语言模型如ChatGPT在解答数学问题方面展现了惊人的能力。尽管它在大多数简单问题上表现出色,但在一些陷阱题上仍可能产生误解,显示出其理解能力的局限性。

在解答线性代数相关的考试题时,ChatGPT能够正确回答大多数问题。然而,某些陷阱题却让它产生误解,显示出该模型在处理复杂逻辑时的不足之处。
1.3 生成考试题
除了回答问题,ChatGPT还能够生成线性代数的考试题。尽管它生成的题目有时可能过于简单,但这展示了它在内容创作方面的潜力。

1.4 GPTS——快速构建AI助手
OpenAI最近推出的新功能GPTS,使得用户可以快速构建AI助手,这为教育领域带来了新的可能性。通过这一功能,用户可以轻松创建个性化的学习助手,提升学习体验。
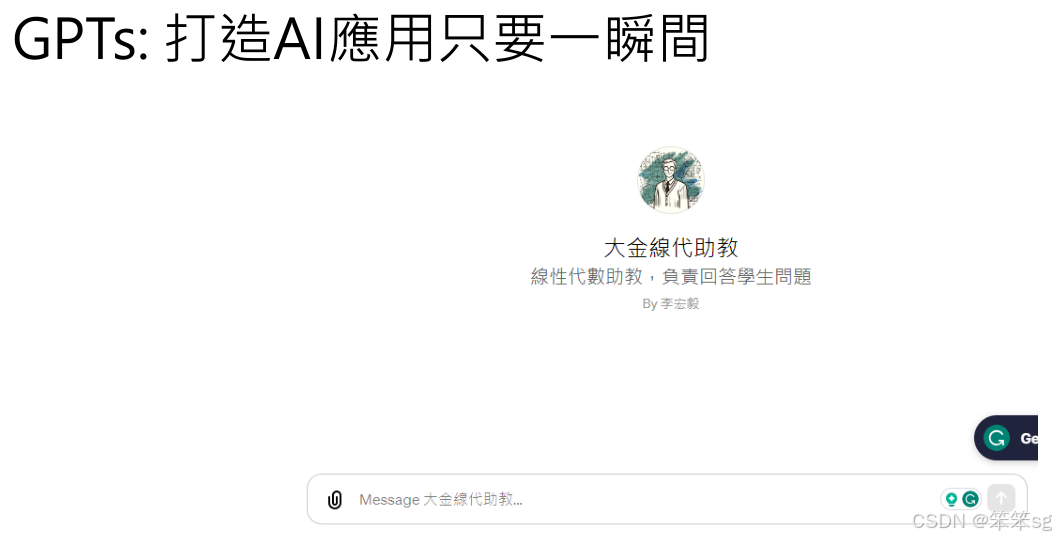
现代的AI助教可以根据课程内容回答特定问题,比如作业内容和截止日期。这种客制化的助手通过输入相关信息快速生成答案,极大提升了学习效率。
大金现代助教不同于传统的ChatGPT,它可以回答特定课程的问题,例如作业内容和截止日期。这种能力使得学生能够更高效地获取所需的信息,减少了疑问和不确定性。
通过简单的设置,任何人都可以在短时间内创建自己的AI助教。只需上传相关课程资料和设置参数,这种自动化过程使得每门课程都能拥有一个专属的AI助手。
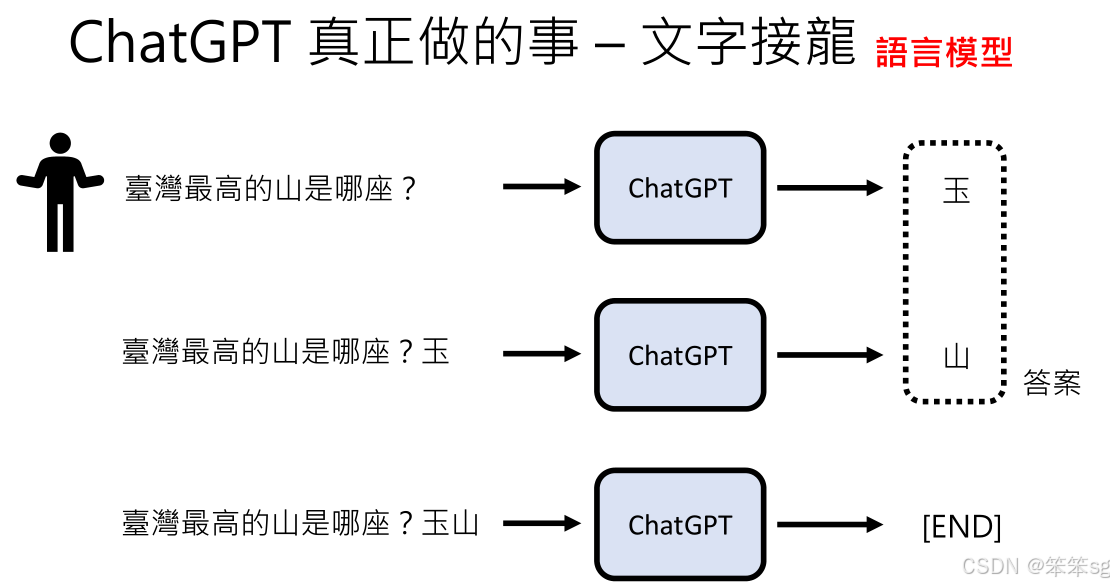
1.5 ChatGPT的运作原理基于文字接龙
输入问题后,AI通过预测下一个最可能的字来生成答案。这种生成式AI的方式让它能够灵活应对各种提问,并提供合理的回答。
1.6 采用掷骰子而不采用贪心解码的原因
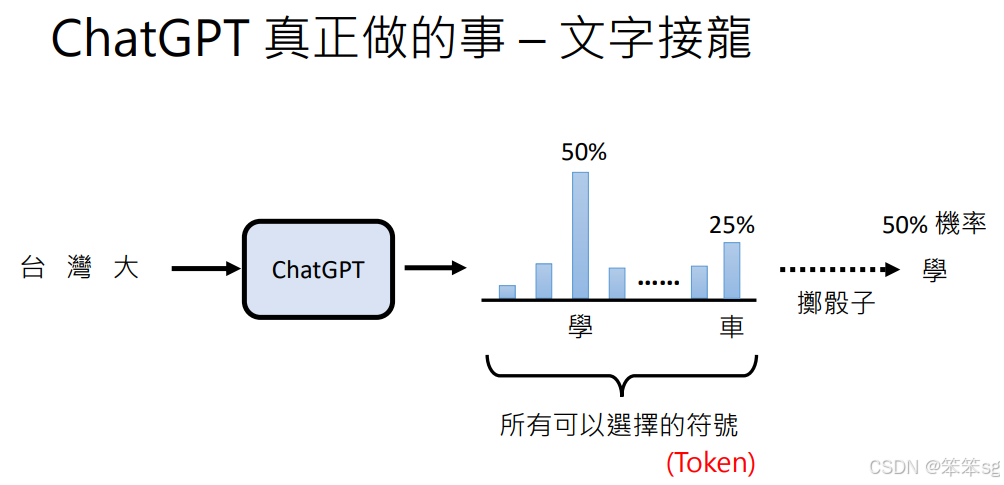
语言模型的输出基于几率分布,通过掷骰子的方式决定最终的输出符号。这个过程使得每次生成的答案可能不同,反映了模型的随机性和灵活性。
那么为啥要掷骰子呢?每次都选择概率最大的token作为输出不好么?

根据19年的一篇文章指出,如果每次都选择概率最大的token作为输出,输出的结果中会有很多重复的单元,而采用掷骰子的方式则会得到更加自然的输出。
示例:
以“贪心解码”为例,假设模型预测下一个词的概率分布为:
- 贪心解码每次都会选择概率最大的词“喜欢”,结果可能是句子反复生成类似“我喜欢……喜欢……喜欢……”的内容。
- 而掷骰子方法会以一定概率选择“爱”或“讨厌”,从而使生成的句子更加自然且多样。
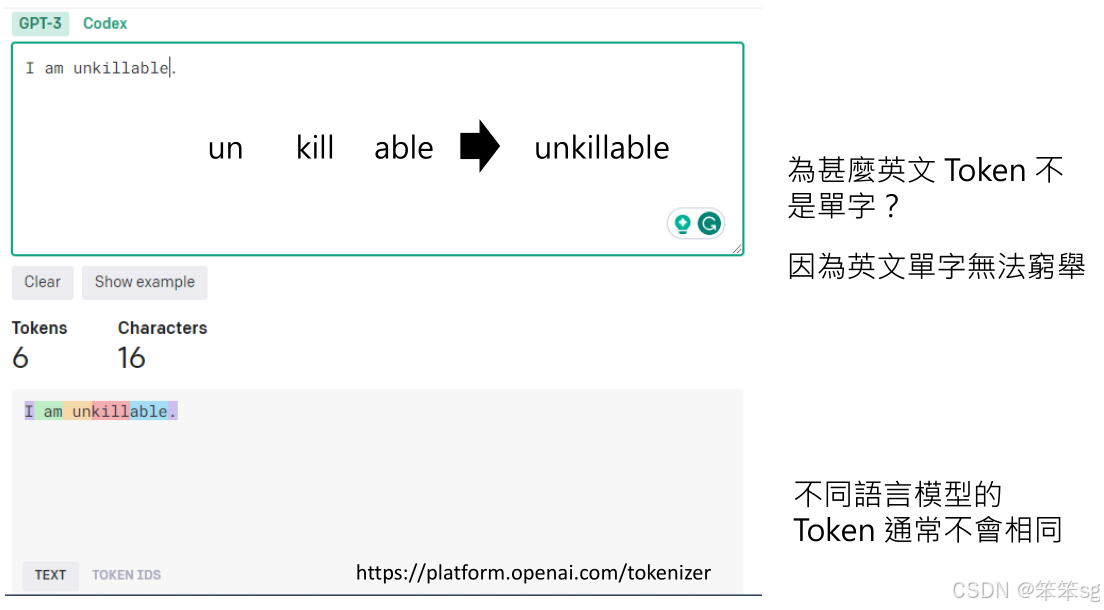
1.7 不同语言模型的Token通常是不同的
Token在语言模型中是一个重要的概念,每个模型定义的token可能不同,影响模型的生成方式。开发者设定的token可以是单词的组成部分,这样可以更好地进行文字接龙。
1.8 出现幻觉的原因
语言模型如ChatGPT在生成内容时,可能会出现不真实的信息。这是因为它的生成过程是基于已输入的内容进行文字接龙,而非基于事实,这导致了偶尔的错误信息输出。

1.9 如何学会的文字接龙?
语言模型通过大量文本资料学习进行文字接龙,ChatGPT的能力体现在它能够处理的对话长度上,甚至能阅读300页的PDF文档。这种学习方式使模型在对话中进行更为复杂的响应,体现了其智能化的特征。
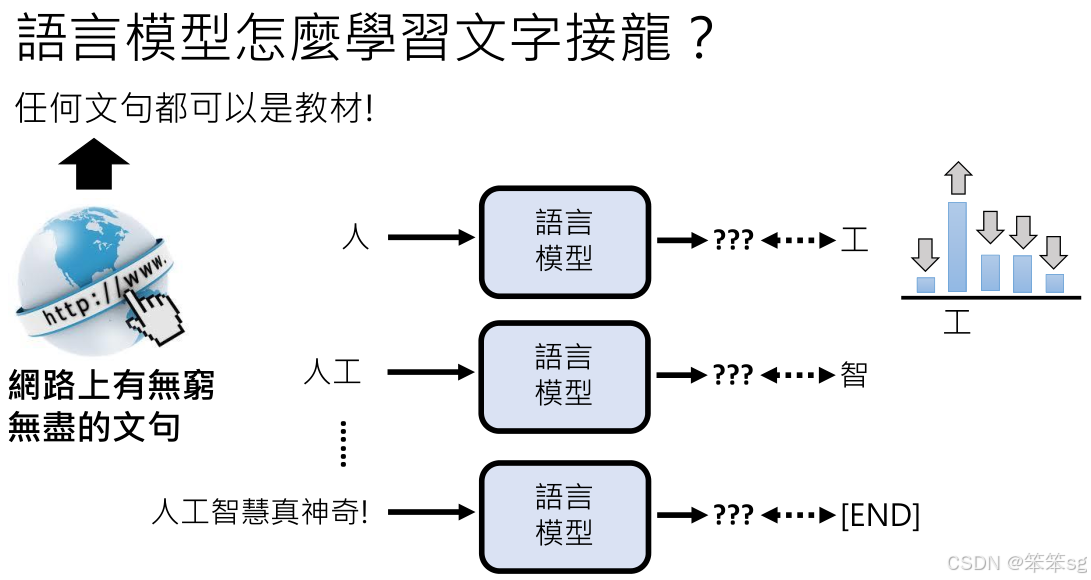
语言模型的学习过程涉及到几率分布的调整,这意味着模型能够根据输入的内容来决定输出的词汇。通过这种方式,模型学会了如何在上下文中选择合适的词语,以生成流畅的句子。
1.10 具备记忆性,支持历史对话
ChatGPT在文字接龙中,不仅依赖当前输入,还结合历史对话内容。这种方法让模型在生成回答时,能够融合之前的上下文,从而输出更相关和连贯的内容。
1.11 参数量逐渐递增
OpenAI的GPT系列模型自2018年开始发展,第一代模型虽然参数相对较少,但为后续的进步奠定了基础。随着技术的进步,第二代模型的参数数量大幅增加,提升了模型的表现能力。
OpenAI在2019年就期望GDQ能成为通用人工智能。尽管GPT-2的表现不佳,但随后推出的GPT-3以其巨大的参数量和知识储备引发了广泛关注和讨论。

GPT-2的表现相对较差,正确率仅为55%。相比之下,人类的正确率达到了90%,显示出人工智能在理解和回答问题上的局限性。

GPT-3的参数量高达1750亿,读过580GB的数据,相当于阅读哈利波特全集30万遍。这使得GPT-3在自然语言生成和理解上展现出强大的潜力。
尽管GPT-3的能力引起惊讶,但在许多任务上的表现仍然差强人意。这表明人工智能需要更好地理解人类的需求和社会规则,以提高其表现。
1.12 预训练和监督式学习
预训练是人工智能成功的重要技术,尤其是在模型的持续学习和微调方面起着关键作用。这种方法使得人工智能能够更好地为人类服务,并提升其整体能力。
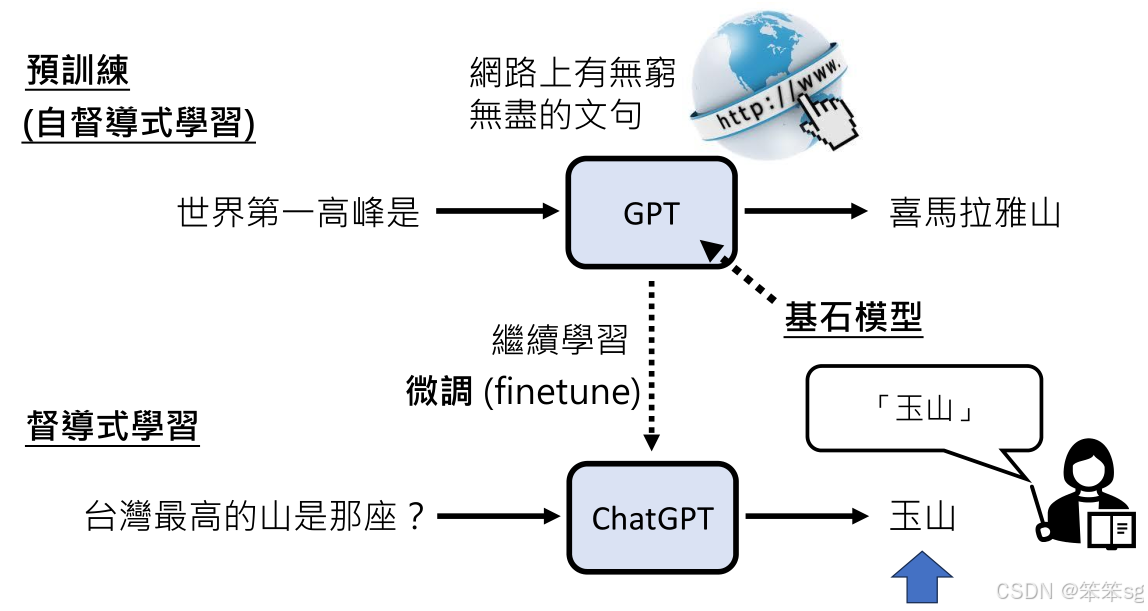
督导式学习对模型的性能有显著影响,能够通过人类的指导提升小模型的能力。即使是较小的模型,在有良好的教学支持下,也能超越大型模型的表现。
通过预训练,模型只需少量的人类指导就能掌握复杂任务。这种方法显示出即使是资源有限的情况下,模型也能通过有效的学习实现优异表现。

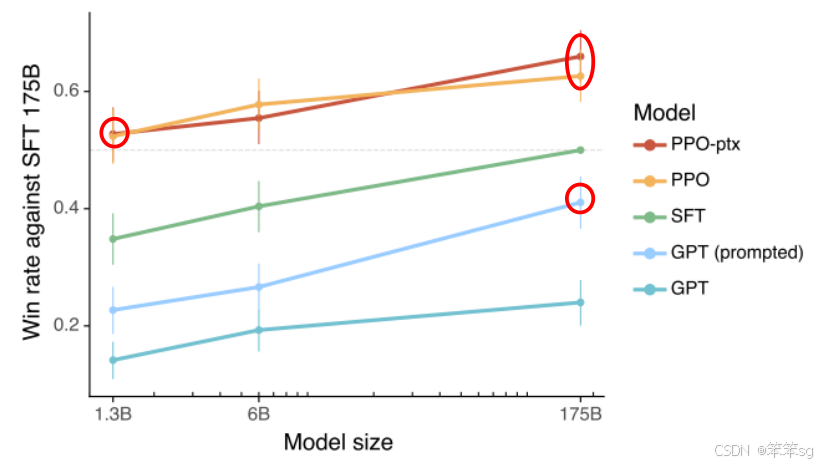
1.13 强化学习
强化学习为模型提供了进一步优化的途径,帮助其在实际应用中不断提高能力。通过这种学习方式,模型能够在不同的任务中灵活应对,提升其应用广度。
强化学习是一种新的学习方式,其中人类老师提供反馈而非直接答案,允许模型根据反馈进行自我调整。这个方法使得每个人都能参与到模型的训练中,降低了人类的工作负担。
强化学习的基本概念是通过人类的反馈来优化模型的回答。当用户在使用模型时,提供的反馈可以帮助模型提高正确答案的概率,并降低错误答案的概率。
在整个训练过程中,增强式学习被安排在最后阶段,因为模型需要具备一定能力才能有效学习。预训练和督导式学习为增强式学习奠定了基础,使模型能够正确理解用户需求。
增强式学习分为两个步骤:首先学习人类老师的偏好,然后使用奖励模型模仿这种偏好。通过这种方式,模型可以在无需人类干预的情况下,自主提高回答质量。
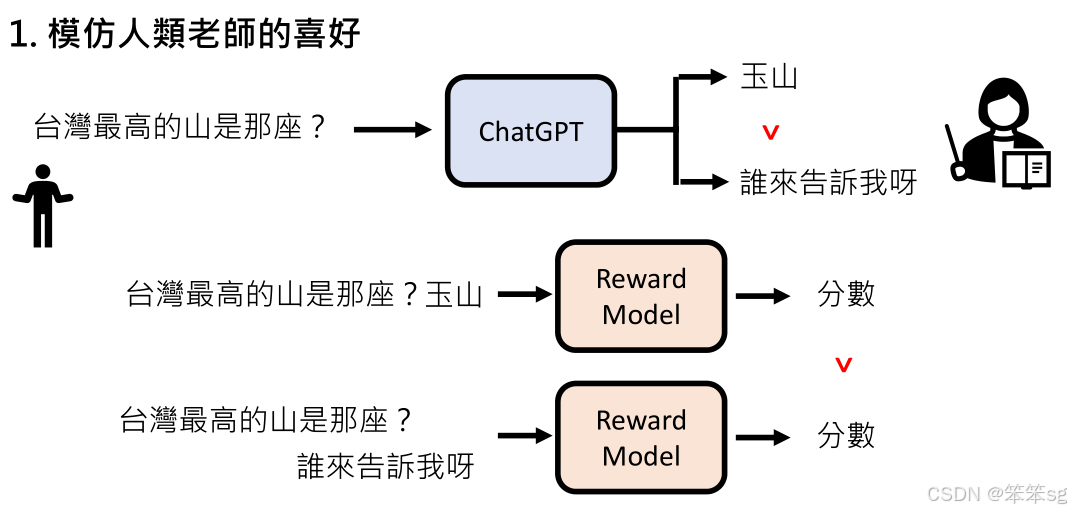
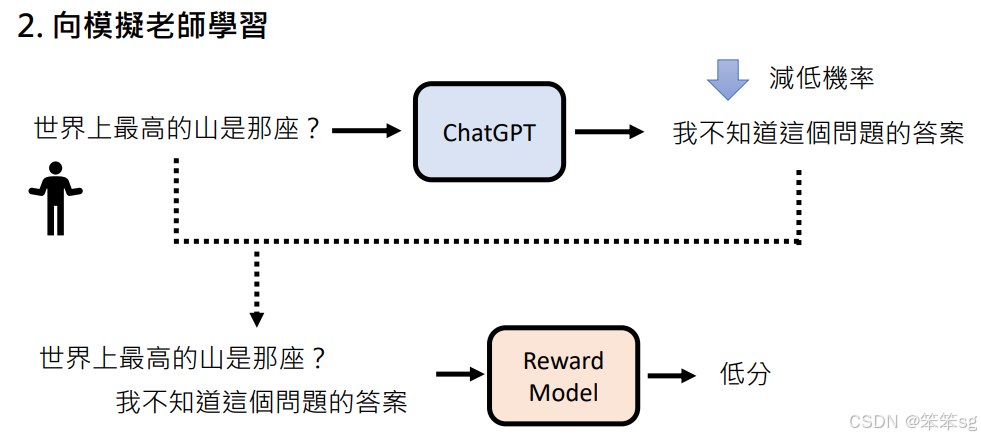
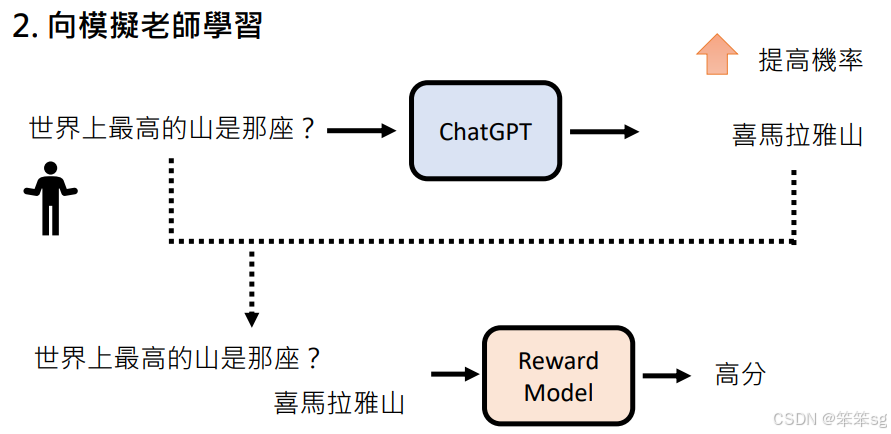
1.14 人类使用GPT时该做的努力
语言模型的能力已经相当强大,但要充分发挥其潜力,人类需要明确表达自己的需求。通过明确的指令和具体的例子,可以有效激发语言模型的创造力和准确性。
1.14.1 清晰表达需求
清晰表达需求是使用语言模型的第一步。许多人在与语言模型互动时没有明确说明想要什么,导致模型无法提供理想的输出,因此提供具体的要求是非常重要的。


1.14.2 提供资讯給 ChatGPT
提供相关信息和背景资料可以帮助语言模型更准确地完成任务。用户应收集必要的数据,并在请求中包含这些信息,以便模型能够更有效地生成符合需求的内容。

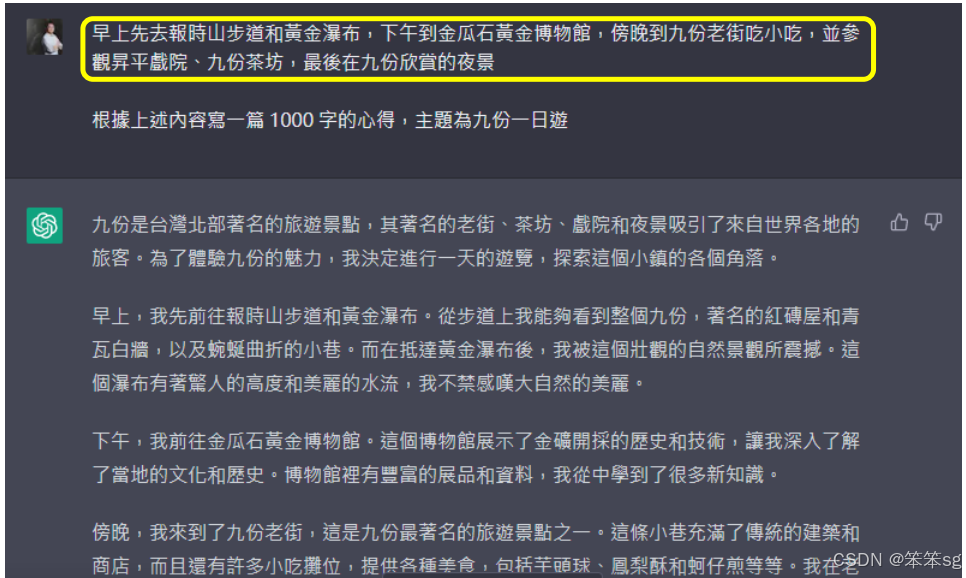
1.14.3 提供范例
使用范例可以帮助模型理解复杂的指令。给语言模型提供示例可以让它更好地抓住用户的意图,从而生成更符合预期的文本。


1.14.4 鼓励GPT思考
鼓励GPT思考的指令显著提升了其解题能力。例如,当要求其详细列出计算过程时,正确率从零提升至80%。这表明,通过合理的引导,可以有效提高AI的表现。

研究表明,使用特定的语言提示可以显著提高AI模型在数学应用题上的回答准确率。例如,简单的鼓励语句如"Let's think"就能将准确率提升至57%。
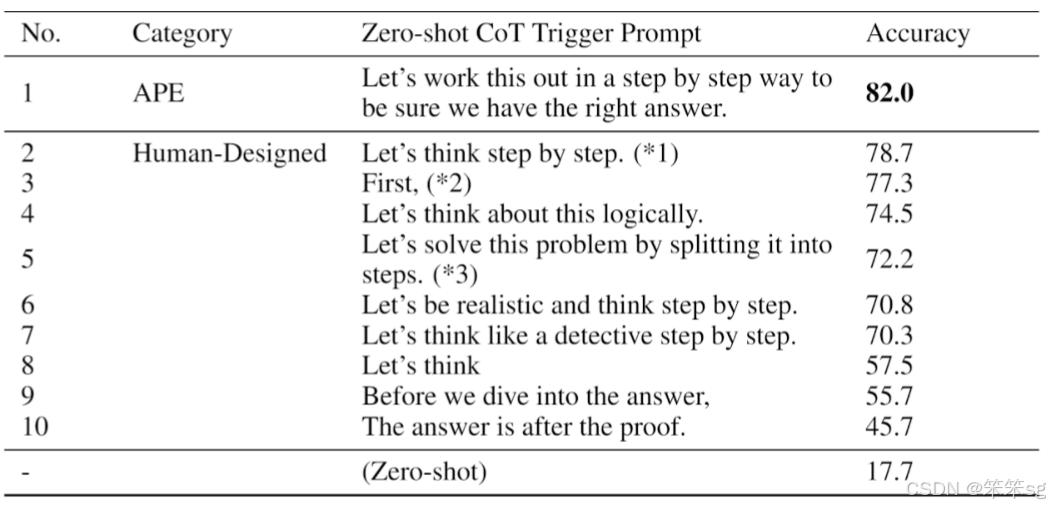
逐步引导AI思考的指令更是提升了其能力,使用"Let's work this out in the step by step way to be sure we have the right answer",准确率可达到82%。这种方法强调了过程的重要性。
1.14.5 利用AI生成送给AI的提示词
利用AI生成有效的提示语也是一种创新的方法。通过训练生成器,该方法能够找到最佳的提示语,从而进一步提升AI的回答质量和准确性。
1.14.6 上传文档
和1.14.2的思想类似。
1.15 GPT调用外部工具
GPT的能力可以通过调用近1000个外挂工具来提升,这使得用户能够获得更准确和相关的信息。尽管如此,使用这些工具并不保证结果的绝对正确性,仍需谨慎使用。
在没有工具的情况下,GPT能提供一些文章链接,虽然结果有时是正确的,但也可能出现错误的情况。这显示了工具使用的重要性和潜在的局限性。
当GPT调用nl paper reader等工具时,它能够依赖更准确的数据库来获取相关信息。这种方式可以增加结果的可靠性,但仍然不能保证100%准确。

GPT与搜索引擎的结合虽然提高了信息获取的效率,但其基本依然是通过文字接龙的方式生成答案,仍然可能会出现错误。用户在使用时需保持警惕。
1.16 拆解任务
目前的语言模型在处理复杂任务时还存在一定的局限性,尤其是在执行具体的步骤时可能会遇到困难。尽管它们能够帮助将大任务拆解成小任务,但在现实应用中仍需进一步的优化和发展。

许多平台如auto GPT和agent等,致力于将复杂任务转变为可管理的小任务。这种拆解过程看似理想,但在实际操作中,语言模型的能力仍显不足,需进一步验证其有效性。
1.17 GPT其实是会反省的
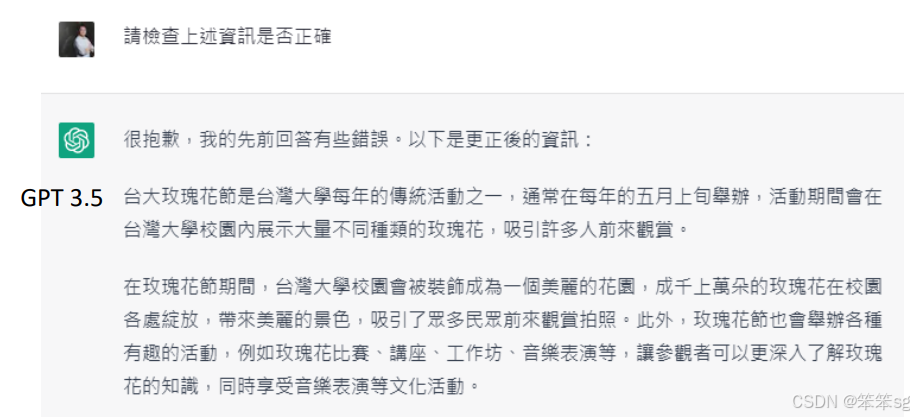
语言模型在自我反省方面的能力有显著差异。以GPT4和GPT3.5为例,前者能够识别并纠正错误,而后者则无法理解其错误,这表明技术的进步对模型的自我提升至关重要。
GPT4:


GPT3.5:


1.18 和真实环境互动
研究者们正在探索如何让语言模型与现实环境互动,以增强其实用性。通过将外部信息转化为文本或图像,语言模型将能更好地理解和处理现实世界中的复杂情况。
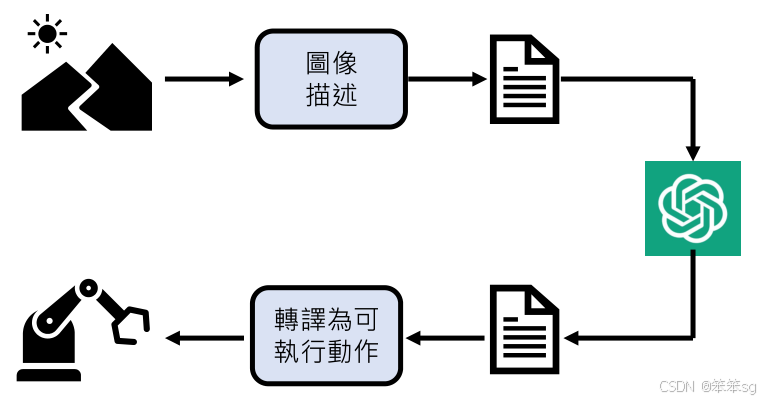
大型语言模型能够将自然语言描述转化为可执行的动作,从而与现实环境进行互动。这为机械手臂等自动化设备提供了更具实用性的应用场景,增强了人工智能的功能和适用性。
通过使用大型语言模型,用户能够给出具体任务,例如将桌上的物品放入背包,并获得清晰的执行步骤。这表明,机器能够更好地理解人类的指令,并将其转化为实际操作。

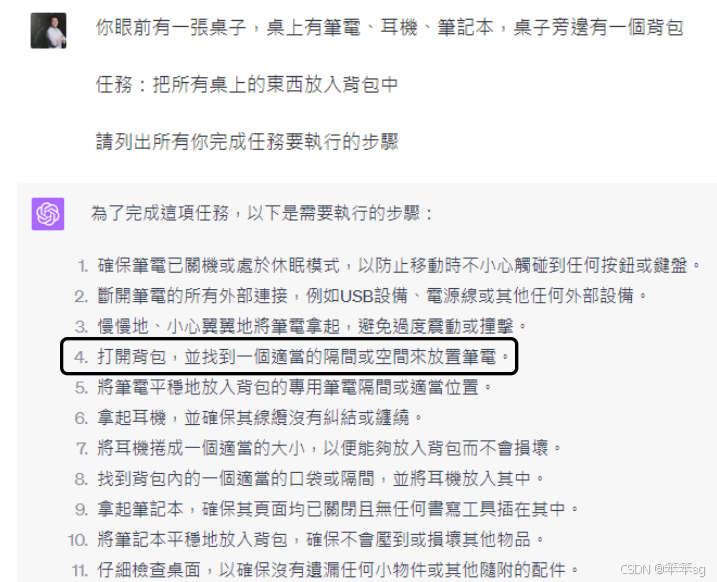

尽管大型语言模型可以生成执行步骤,但这些步骤对于机械手臂而言仍显得抽象。因此,需要进一步将语言描述转化为机械手臂能够理解和执行的具体动作。
生成式人工智能的应用潜力巨大,视频中仅仅展示了冰山一角。学习更多相关技术能够帮助人们更好地理解和运用这些先进的人工智能工具。
评论记录:
回复评论: