
目前大模型部署工具主要是vllm,最近出现了SGLang,很多新开源大模型都支持SGLang的部署推理,例如deepseek-R1,Qwen2.5,Mistral,GLM-4,MiniCPM 3,InternLM 2, Llama 3.2
等。
文档:SGLang Documentation — SGLang
下面介绍 DeepSeek-R1-Distill-Qwen-7B 的 SGLang推理:
1. 环境搭建。
很多人在环境搭建这一步就放弃了,因为环境搭建真的不好弄。有很多坑。。。
创建虚拟环境
- conda create -n sglang python=3.12
-
- conda activate sglang
-
- pip install vllm
-
- # 安装最新的版本
-
- pip install sglang==0.4.1.post7
-
- pip install sgl_kernel
-
如果提示
- from flashinfer import (
- ModuleNotFoundError: No module named 'flashinfer'
请先下载 flashinfer 的安装 whl 包,然后用 pip 安装。
flashinfer 的安装包下载地址:Installation - FlashInfer 0.2.0.post1 documentation
各个版本地址:https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/
下载匹配你环境的版本吧,我是pytorch2.5.1,安装的 flashinfer-0.2.0.post1+cu124torch2.4-cp312-cp312-linux_x86_64.whl ,运行程序没有问题。
- wget https://github.com/flashinfer-ai/flashinfer/releases/download/v0.2.0/flashinfer-0.2.0+cu124torch2.4-cp312-cp312-linux_x86_64.whl#sha256=a743e156971aa3574faf91e1090277520077a6dd5e24824545d03ce9ed5a3f59
-
- pip install flashinfer-0.2.0.post1+cu124torch2.4-cp312-cp312-linux_x86_64.whl --no-deps
一定要加上参数--no-deps,不然安装的时候会自动下载pytorch2.4。
2. 启动服务。
python3 -m sglang.launch_server --model ./DeepSeek-R1-Distill-Qwen-7B --host 0.0.0.0 --port 8123模型文件我已经下载到当前路径的 DeepSeek-R1-Distill-Qwen-7B 文件夹了。下载方法:如何快速下载Huggingface上的超大模型,不用梯子,以Deepseek-R1为例子-CSDN博客
- [2025-01-23 11:42:18] server_args=ServerArgs(model_path='./DeepSeek-R1-Distill-Qwen-7B', tokenizer_path='./DeepSeek-R1-Distill-Qwen-7B', tokenizer_mode='auto', load_format='auto', trust_remote_code=False, dtype='auto', kv_cache_dtype='auto', quantization_param_path=None, quantization=None, context_length=None, device='cuda', served_model_name='./DeepSeek-R1-Distill-Qwen-7B', chat_template=None, is_embedding=False, revision=None, skip_tokenizer_init=False, host='0.0.0.0', port=8099, mem_fraction_static=0.88, max_running_requests=None, max_total_tokens=None, chunked_prefill_size=2048, max_prefill_tokens=16384, schedule_policy='lpm', schedule_conservativeness=1.0, cpu_offload_gb=0, prefill_only_one_req=False, tp_size=1, stream_interval=1, random_seed=398925437, constrained_json_whitespace_pattern=None, watchdog_timeout=300, download_dir=None, base_gpu_id=0, log_level='info', log_level_http=None, log_requests=False, show_time_cost=False, enable_metrics=False, decode_log_interval=40, api_key=None, file_storage_pth='sglang_storage', enable_cache_report=False, dp_size=1, load_balance_method='round_robin', ep_size=1, dist_init_addr=None, nnodes=1, node_rank=0, json_model_override_args='{}', lora_paths=None, max_loras_per_batch=8, attention_backend='flashinfer', sampling_backend='flashinfer', grammar_backend='outlines', speculative_draft_model_path=None, speculative_algorithm=None, speculative_num_steps=5, speculative_num_draft_tokens=64, speculative_eagle_topk=8, enable_double_sparsity=False, ds_channel_config_path=None, ds_heavy_channel_num=32, ds_heavy_token_num=256, ds_heavy_channel_type='qk', ds_sparse_decode_threshold=4096, disable_radix_cache=False, disable_jump_forward=False, disable_cuda_graph=False, disable_cuda_graph_padding=False, disable_outlines_disk_cache=False, disable_custom_all_reduce=False, disable_mla=False, disable_overlap_schedule=False, enable_mixed_chunk=False, enable_dp_attention=False, enable_ep_moe=False, enable_torch_compile=False, torch_compile_max_bs=32, cuda_graph_max_bs=8, cuda_graph_bs=None, torchao_config='', enable_nan_detection=False, enable_p2p_check=False, triton_attention_reduce_in_fp32=False, triton_attention_num_kv_splits=8, num_continuous_decode_steps=1, delete_ckpt_after_loading=False, enable_memory_saver=False, allow_auto_truncate=False, enable_custom_logit_processor=False)
- [2025-01-23 11:42:24 TP0] Init torch distributed begin.
- [2025-01-23 11:42:25 TP0] Load weight begin. avail mem=23.25 GB
- Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00
- Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:01<00:01, 1.07s/it]
- Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:02<00:00, 1.47s/it]
- Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:02<00:00, 1.41s/it]
-
- [2025-01-23 11:42:28 TP0] Load weight end. type=Qwen2ForCausalLM, dtype=torch.bfloat16, avail mem=8.86 GB
- [2025-01-23 11:42:28 TP0] KV Cache is allocated. K size: 3.04 GB, V size: 3.04 GB.
- [2025-01-23 11:42:28 TP0] Memory pool end. avail mem=1.74 GB
- [2025-01-23 11:42:28 TP0] Capture cuda graph begin. This can take up to several minutes.
- 25%|████████████████████████████ | 50%|████████████████████████████████████████████████████████ 75%|███████████████████████████████████████████████████████████████████████100%|███████████████████████████████████████████████████████████████████████100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:02<00:00, 1.96it/s]
- [2025-01-23 11:42:30 TP0] Capture cuda graph end. Time elapsed: 2.05 s
- [2025-01-23 11:42:30 TP0] max_total_num_tokens=113727, max_prefill_tokens=16384, max_running_requests=2049, context_len=131072
- [2025-01-23 11:42:31] INFO: Started server process [1091415]
- [2025-01-23 11:42:31] INFO: Waiting for application startup.
- [2025-01-23 11:42:31] INFO: Application startup complete.
- [2025-01-23 11:42:31] INFO: Uvicorn running on http://0.0.0.0:8099 (Press CTRL+C to quit)
- [2025-01-23 11:42:32] INFO: 127.0.0.1:52354 - "GET /get_model_info HTTP/1.1" 200 OK
- [2025-01-23 11:42:32 TP0] Prefill batch. #new-seq: 1, #new-token: 6, #cached-token: 0, cache hit rate: 0.00%, token usage: 0.00, #running-req: 0, #queue-req: 0
- [2025-01-23 11:42:33] INFO: 127.0.0.1:52368 - "POST /generate HTTP/1.1" 200 OK
- [2025-01-23 11:42:33] The server is fired up and ready to roll!
看到以上信息说明服务启动成功, 9B模型占用显存 23 GB。
3. 测试。
测试代码
- import openai
-
- client = openai.Client(base_url="http://localhost:8123/v1", api_key="None")
-
- response = client.chat.completions.create(
- model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
- messages=[
- {"role": "user", "content": "如何预防肺癌?"},
- ],
- temperature=0,
- max_tokens=4096,
- )
- print(response.choices[0].message.content)
返回结果:

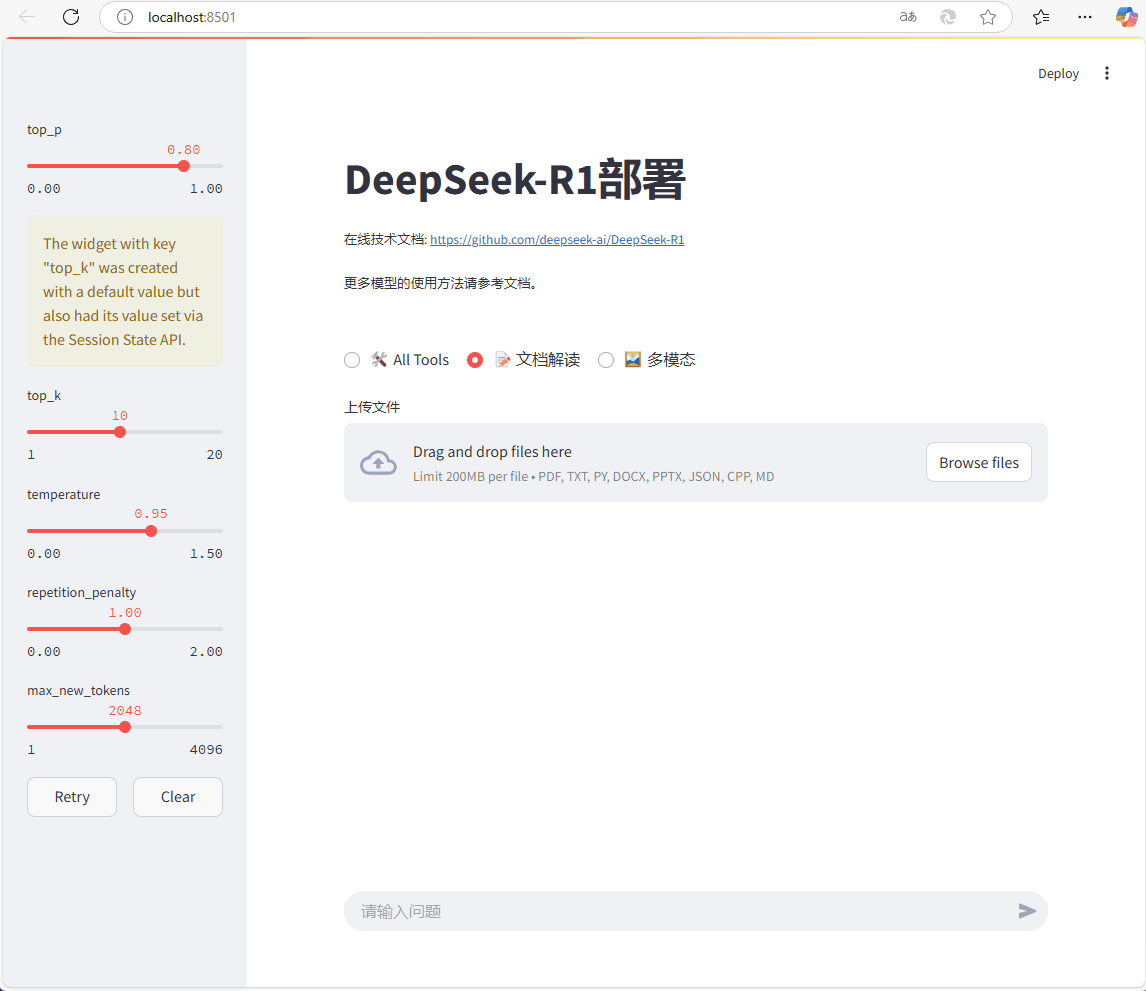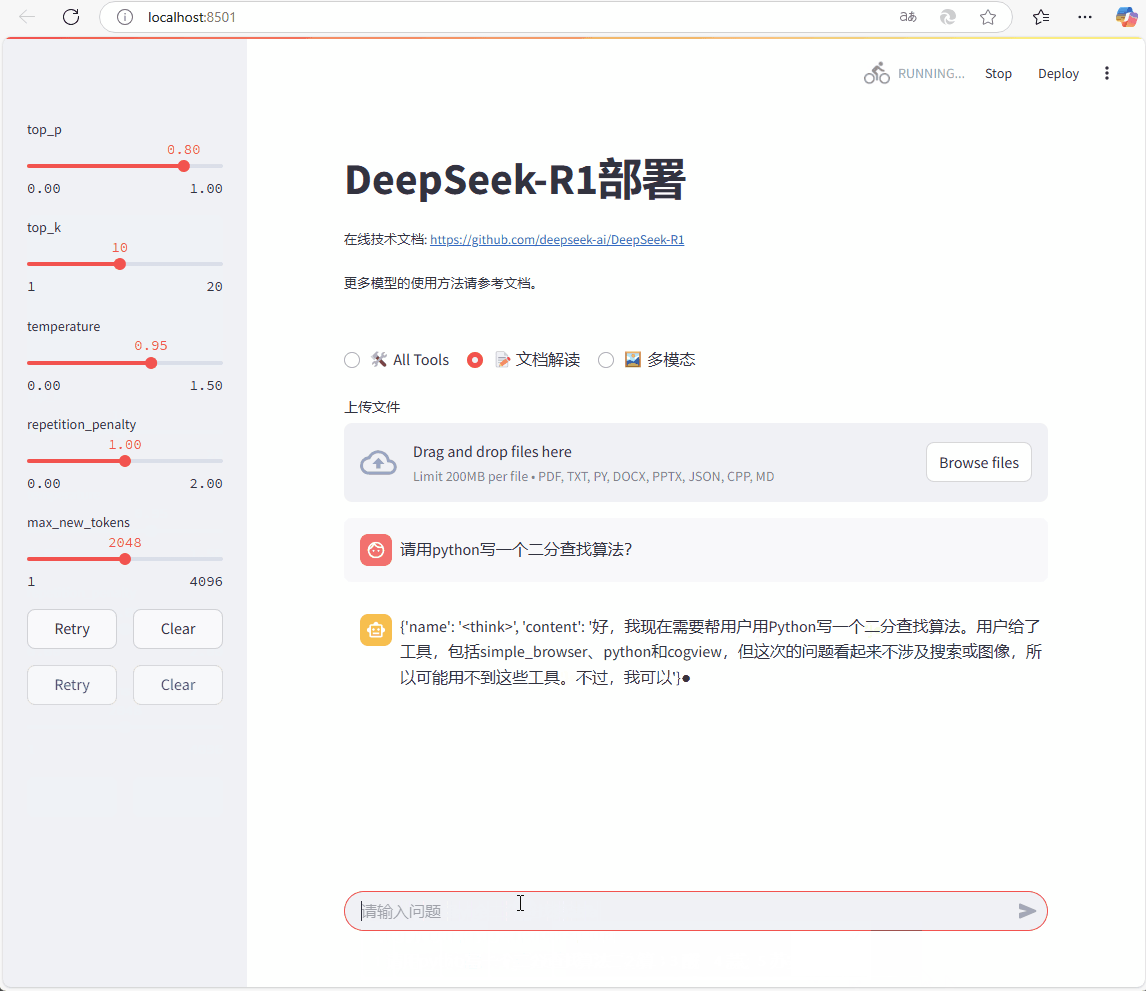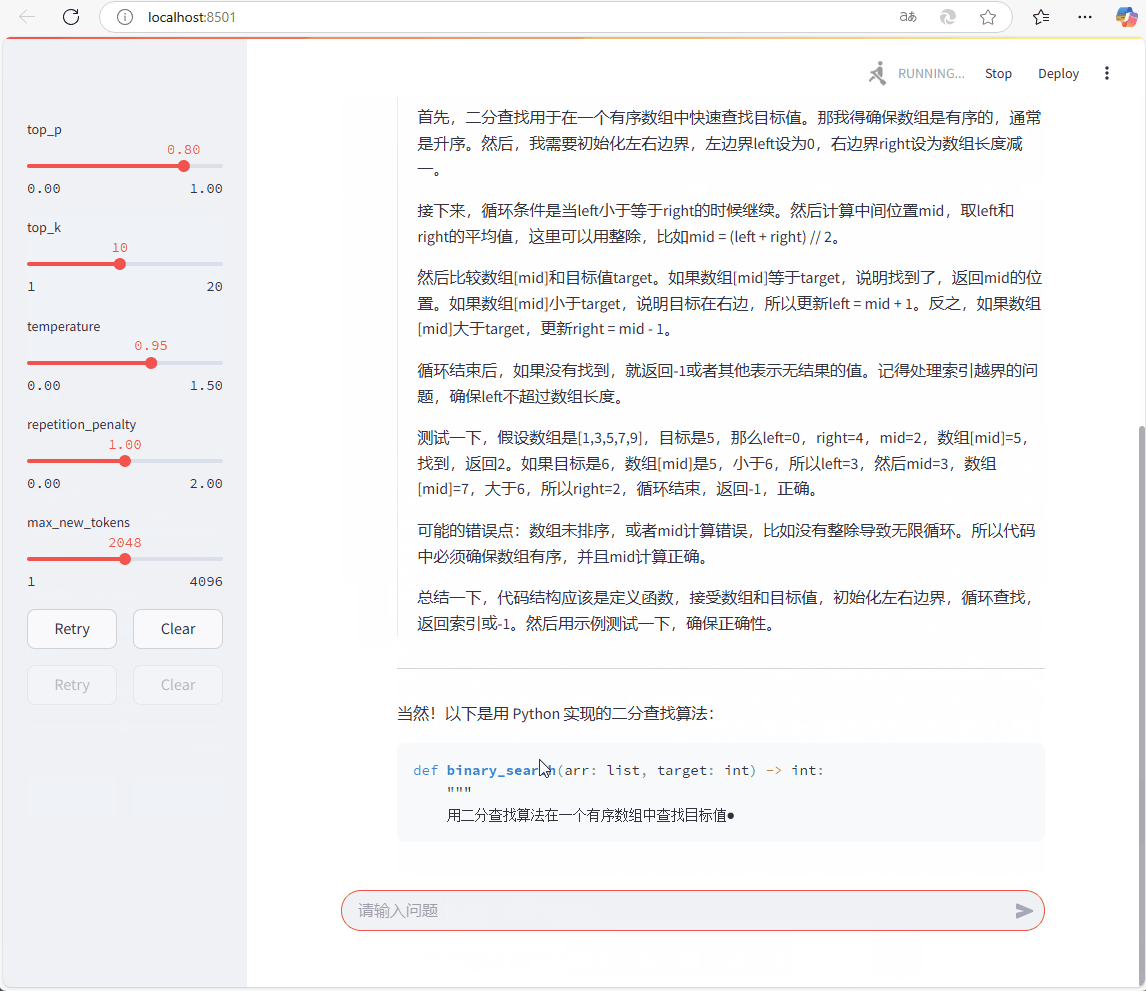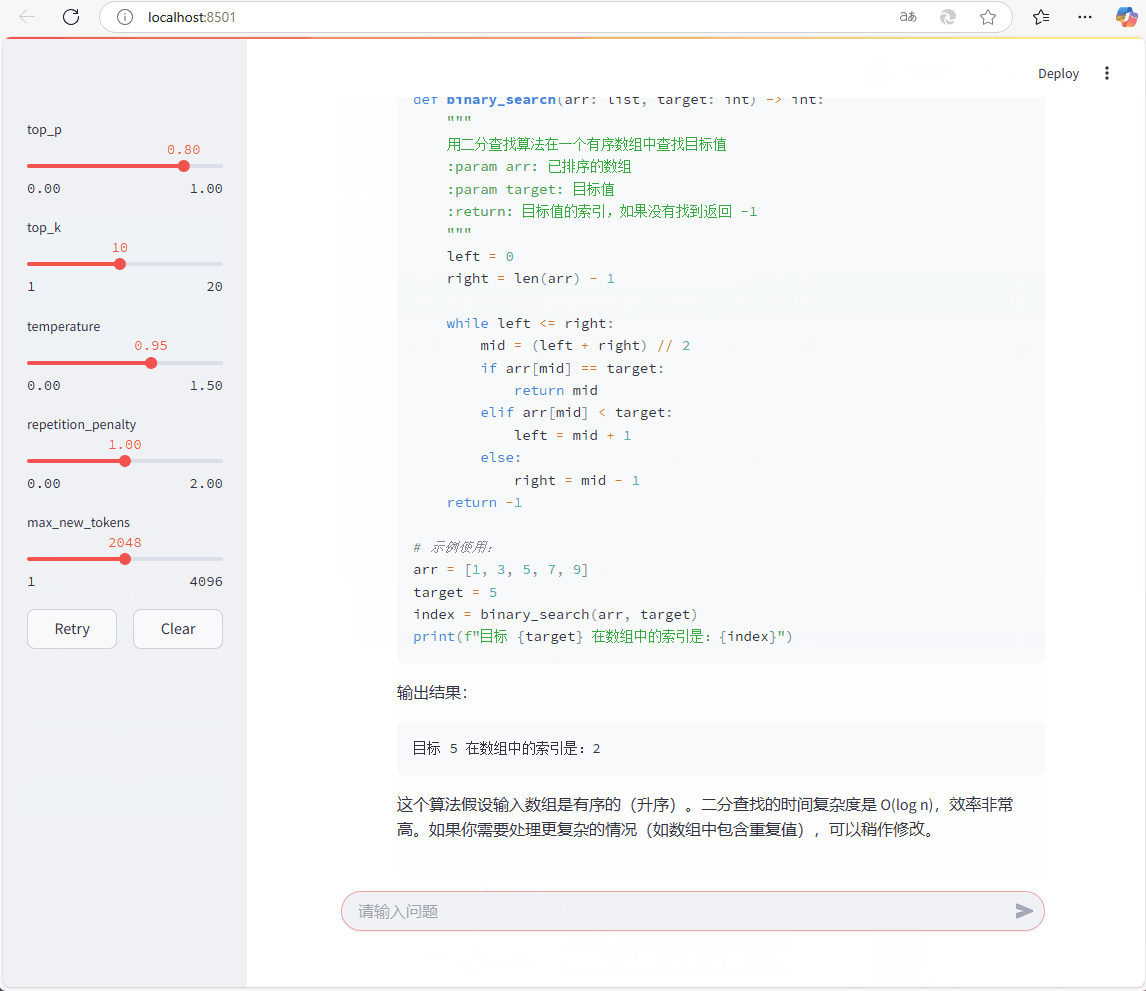
采用streamlit 、 langchain 和 SGLang 部署 deepseek。
评论记录:
回复评论: