def_inject_data_into_chromadb(self):
chroma_client = self.APPCFG.chroma_client
existing_collections = chroma_client.list_collections()
collection_name = self.APPCFG.collection_name
existing_collection_names =[collection.name for collection in existing_collections]if collection_name in existing_collection_names:
collection = chroma_client.get_collection(name=collection_name)print(f"Retrieved existing collection: {collection_name}")else:
collection = chroma_client.create_collection(name=collection_name)print(f"Created new collection: {collection_name}")
collection.add(
documents=self.docs,
metadatas=self.metadatas,
embeddings=self.embeddings,
ids=self.ids
)print("Data is stored in ChromaDB.")
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
class="hide-preCode-box">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
功能:
检查集合是否已存在。如果存在,则获取;否则,创建新集合。
将文档、元数据、嵌入向量和 ID 添加到集合中。
异常处理:
避免重复创建集合。
7. 验证数据库内容 (_validate_db)
def_validate_db(self):
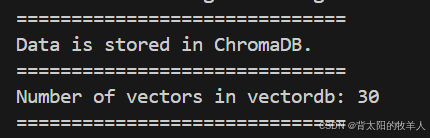
vectordb = self.APPCFG.chroma_client.get_collection(name=self.APPCFG.collection_name)print("Number of vectors in vectordb:", vectordb.count())
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
1
2
3
功能:
获取集合并打印其中向量的数量,确认数据是否注入成功。
代码运行结果:
总结
这段代码的整体流程如下:
加载 CSV 或 Excel 文件,转换为 Pandas DataFrame。
遍历 DataFrame 的每一行,生成文档、元数据和嵌入向量。
将生成的数据注入到 ChromaDB 的集合中。
验证数据库集合中的向量数量,确保注入成功。
需要注意文件格式支持、嵌入生成器和 ChromaDB 客户端的兼容性问题。
完整代码:
import os
import pandas as pd
from utils.load_config import LoadConfig
import pandas as pd
classPrepareVectorDBFromTabularData:"""
This class is designed to prepare a vector database from a CSV and XLSX file.
It then loads the data into a ChromaDB collection. The process involves
reading the CSV file, generating embeddings for the content, and storing
the data in the specified collection.
Attributes:
APPCFG: Configuration object containing settings and client instances for database and embedding generation.
file_directory: Path to the CSV file that contains data to be uploaded.
"""def__init__(self, file_directory:str)->None:"""
Initialize the instance with the file directory and load the app config.
Args:
file_directory (str): The directory path of the file to be processed.
"""
self.APPCFG = LoadConfig()
self.file_directory = file_directory
defrun_pipeline(self):"""
Execute the entire pipeline for preparing the database from the CSV.
This includes loading the data, preparing the data for injection, injecting
the data into ChromaDB, and validating the existence of the injected data.
"""
self.df, self.file_name = self._load_dataframe(file_directory=self.file_directory)
self.docs, self.metadatas, self.ids, self.embeddings = self._prepare_data_for_injection(df=self.df, file_name=self.file_name)
self._inject_data_into_chromadb()
self._validate_db()def_load_dataframe(self, file_directory:str):"""
Load a DataFrame from the specified CSV or Excel file.
Args:
file_directory (str): The directory path of the file to be loaded.
Returns:
DataFrame, str: The loaded DataFrame and the file's base name without the extension.
Raises:
ValueError: If the file extension is neither CSV nor Excel.
"""
file_names_with_extensions = os.path.basename(file_directory)print(file_names_with_extensions)
file_name, file_extension = os.path.splitext(
file_names_with_extensions)if file_extension ==".csv":
df = pd.read_csv(file_directory)return df, file_name
elif file_extension ==".xlsx":
df = pd.read_excel(file_directory)return df, file_name
else:raise ValueError("The selected file type is not supported")def_prepare_data_for_injection(self, df:pd.DataFrame, file_name:str):"""
Generate embeddings and prepare documents for data injection.
Args:
df (pd.DataFrame): The DataFrame containing the data to be processed.
file_name (str): The base name of the file for use in metadata.
Returns:
list, list, list, list: Lists containing documents, metadatas, ids, and embeddings respectively.
"""
docs =[]
metadatas =[]
ids =[]
embeddings =[]for index, row in df.iterrows():
output_str =""# Treat each row as a separate chunkfor col in df.columns:
output_str +=f"{col}: {row[col]},\n"
response = self.APPCFG.OpenAIEmbeddings.embed_documents(output_str)[0]
embeddings.append(response)
docs.append(output_str)
metadatas.append({"source": file_name})
ids.append(f"id{index}")return docs, metadatas, ids, embeddings
def_inject_data_into_chromadb(self):"""
Inject the prepared data into ChromaDB.
Raises an error if the collection_name already exists in ChromaDB.
The method prints a confirmation message upon successful data injection.
"""
chroma_client = self.APPCFG.chroma_client
# 列出所有集合的名称
existing_collections = chroma_client.list_collections()
collection_name = self.APPCFG.collection_name #"titanic_small"# 获取所有集合
existing_collections = chroma_client.list_collections()# 提取集合名称
existing_collection_names =[collection.name for collection in existing_collections]if collection_name in existing_collection_names:# 如果集合存在,获取它
collection = chroma_client.get_collection(name=collection_name)print(f"Retrieved existing collection: {collection_name}")else:# 如果集合不存在,创建它
collection = chroma_client.create_collection(name=collection_name)print(f"Created new collection: {collection_name}")
collection.add(
documents=self.docs,
metadatas=self.metadatas,
embeddings=self.embeddings,
ids=self.ids
)print("==============================")print("Data is stored in ChromaDB.")def_validate_db(self):"""
Validate the contents of the database to ensure that the data injection has been successful.
Prints the number of vectors in the ChromaDB collection for confirmation.
"""
vectordb = self.APPCFG.chroma_client.get_collection(name=self.APPCFG.collection_name)print("==============================")print("Number of vectors in vectordb:", vectordb.count())print("==============================")
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> class="hide-preCode-box">


评论记录:
回复评论: