
一、引言
在当今数字化时代,移动设备已经成为人们生活中不可或缺的一部分,而图像识别技术在移动设备上的应用也日益广泛,如拍照识别物体、实时图像分类等。然而,传统的卷积神经网络(CNN)由于模型庞大、计算复杂,难以直接应用于资源受限的移动设备。MobileNet 的出现,犹如一股清新的春风,为移动设备上的图像识别带来了曙光,它以其轻量级的架构和高效的性能,开启了移动设备图像识别的新篇章。
二、MobileNet 的诞生背景
随着移动互联网的飞速发展,人们对在移动设备上实现高效的图像识别等计算机视觉任务的需求愈发迫切。但移动设备通常具有计算能力有限、内存较小、电池续航能力要求高等特点,传统的深度卷积神经网络模型,如 VGG、ResNet 等,虽然在图像识别任务上表现出色,但它们的参数量和计算量巨大,无法满足移动设备的实际需求。为了解决这一矛盾,谷歌团队提出了 MobileNet,旨在设计一种能够在移动设备上高效运行的轻量级卷积神经网络,同时保持较高的图像识别准确率。
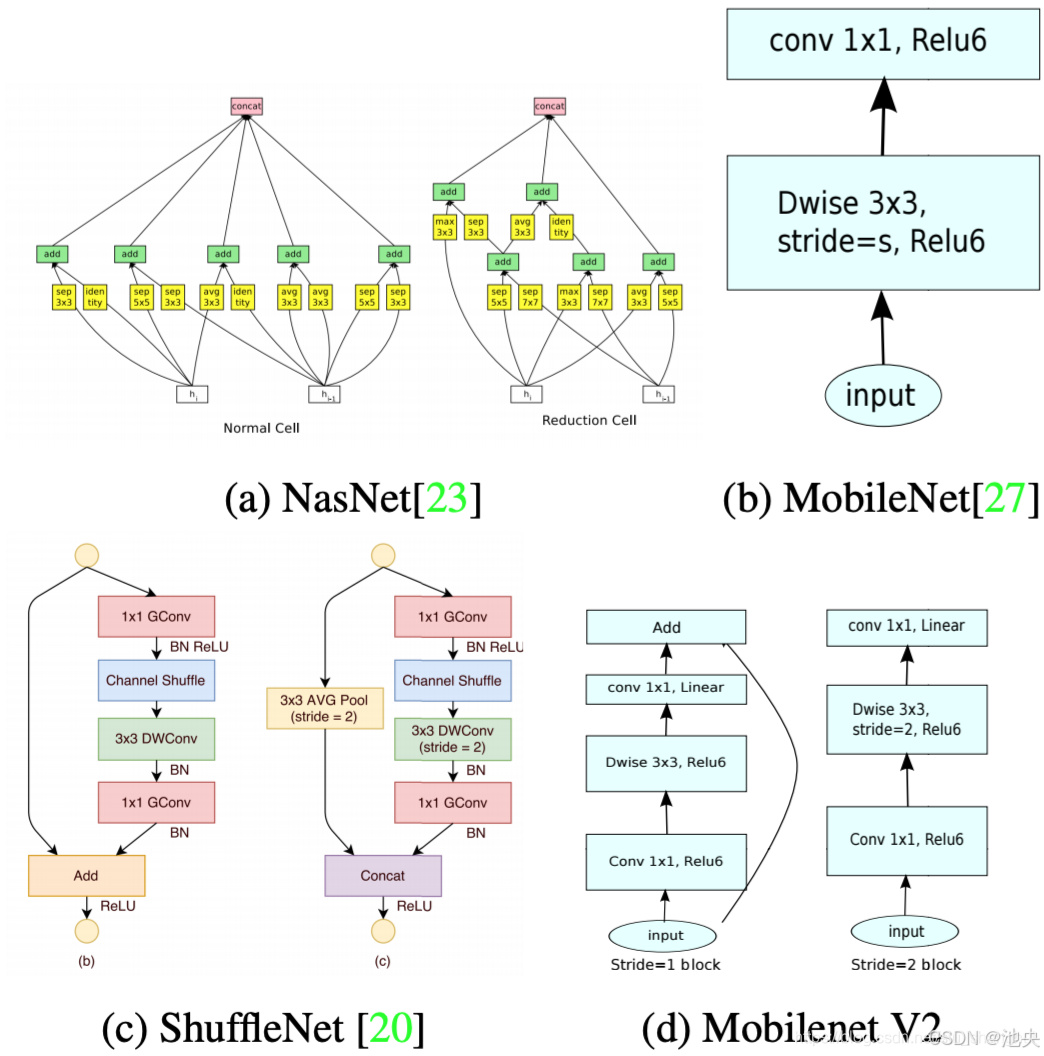
三、MobileNet 的核心原理
(一)深度可分离卷积(Depthwise Separable Convolution)
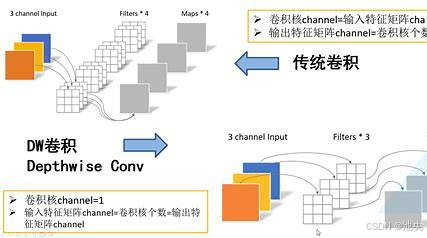
深度可分离卷积是 MobileNet 的核心技术,它将传统卷积操作分解为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个步骤,大大降低了计算量和参数量。
深度卷积:

逐点卷积:

以下是使用 PyTorch 实现深度可分离卷积的示例代码:
import torch
import torch.nn as nn
class DepthwiseSeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(DepthwiseSeparableConv2d, self).__init__()
# 深度卷积
self.depthwise_conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels)
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu = nn.ReLU(inplace=True)
# 逐点卷积
self.pointwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.depthwise_conv(x)
out = self.bn1(out)
out = self.relu(out)
out = self.pointwise_conv(out)
out = self.bn2(out)
out = self.relu(out)
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在上述代码中,DepthwiseSeparableConv2d类定义了一个深度可分离卷积模块。depthwise_conv是深度卷积层,通过设置groups=in_channels实现每个通道单独卷积;pointwise_conv是逐点卷积层,用于改变通道数。forward方法中依次进行深度卷积、批量归一化、ReLU 激活、逐点卷积、批量归一化和 ReLU 激活操作。
(二)宽度因子(Width Multiplier)和分辨率因子(Resolution Multiplier)
四、MobileNet 的网络架构
(一)MobileNet v1 架构
MobileNet v1 的网络结构主要由一系列的深度可分离卷积层和标准卷积层、池化层、全连接层等组成。以下是一个简化版的 MobileNet v1 网络架构示例(以 PyTorch 代码表示):
import torch
import torch.nn as nn
import torch.nn.functional as F
class MobileNetV1(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0):
super(MobileNetV1, self).__init__()
# 定义网络的初始卷积层
self.conv1 = nn.Conv2d(3, int(32 * width_mult), kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(int(32 * width_mult))
self.relu = nn.ReLU(inplace=True)
# 定义一系列的深度可分离卷积模块
def depthwise_separable_conv(in_channels, out_channels, stride):
return nn.Sequential(
DepthwiseSeparableConv2d(in_channels, out_channels, stride=stride),
nn.Dropout(0.2)
)
self.conv2 = depthwise_separable_conv(int(32 * width_mult), int(64 * width_mult), stride=1)
self.conv3 = depthwise_separable_conv(int(64 * width_mult), int(128 * width_mult), stride=2)
self.conv4 = depthwise_separable_conv(int(128 * width_mult), int(128 * width_mult), stride=1)
self.conv5 = depthwise_separable_conv(int(128 * width_mult), int(256 * width_mult), stride=2)
self.conv6 = depthwise_separable_conv(int(256 * width_mult), int(256 * width_mult), stride=1)
self.conv7 = depthwise_separable_conv(int(256 * width_mult), int(512 * width_mult), stride=2)
self.conv8 = depthwise_separable_conv(int(512 * width_mult), int(512 * width_mult), stride=1)
self.conv9 = depthwise_separable_conv(int(512 * width_mult), int(512 * width_mult), stride=1)
self.conv10 = depthwise_separable_conv(int(512 * width_mult), int(512 * width_mult), stride=1)
self.conv11 = depthwise_separable_conv(int(512 * width_mult), int(512 * width_mult), stride=1)
self.conv12 = depthwise_separable_conv(int(512 * width_mult), int(1024 * width_mult), stride=2)
self.conv13 = depthwise_separable_conv(int(1024 * width_mult), int(1024 * width_mult), stride=1)
# 定义平均池化层和全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(int(1024 * width_mult), num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.conv8(x)
x = self.conv9(x)
x = self.conv10(x)
x = self.conv11(x)
x = self.conv12(x)
x = self.conv13(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
卷积模块的堆叠,每个模块由深度卷积和逐点卷积组成,并在某些模块后添加了 Dropout 层以防止过拟合。最后是一个自适应平均池化层和全连接层用于分类。
(二)MobileNet v2 架构
MobileNet v2 在 v1 的基础上进行了改进,主要引入了倒置残差结构(Inverted Residual Block)和线性瓶颈(Linear Bottleneck)。
倒置残差结构:
在传统的残差结构中,通常是先通过一个 1x1 卷积进行降维,然后进行 3x3 卷积等操作,最后再通过一个 1x1 卷积进行升维恢复通道数。而在倒置残差结构中,顺序相反,先通过一个 1x1 卷积进行升维,然后进行深度卷积,最后再通过一个 1x1 卷积进行降维。这样做的好处是,在深度卷积之前增加通道数,可以在低维空间中进行更高效的特征提取,同时减少计算量。
线性瓶颈:
在倒置残差结构的最后一个 1x1 卷积(降维操作)后,不使用 ReLU 激活函数,而是直接输出,即使用线性激活。这是因为 ReLU 激活函数在低维空间中可能会丢失一些信息,而在 MobileNet v2 的这种结构中,最后降维后的特征已经处于较低维度,使用线性激活可以更好地保留信息。
以下是一个 MobileNet v2 中倒置残差结构的示例代码(以 PyTorch 表示):
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = in_channels * expand_ratio
self.use_res_connect = self.stride == 1 and in_channels == out_channels
layers = []
if expand_ratio!= 1:
# 1x1卷积升维
layers.append(nn.Conv2d(in_channels, hidden_dim, kernel_size=1, stride=1, padding=0, bias=False))
layers.append(nn.BatchNorm2d(hidden_dim))
layers.append(nn.ReLU6(inplace=True))
# 深度卷积
layers.append(nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, padding=1, groups=hidden_dim, bias=False))
layers.append(nn.BatchNorm2d(hidden_dim))
layers.append(nn.ReLU6(inplace=True))
# 1x1卷积降维
layers.append(nn.Conv2d(hidden_dim, out_channels, kernel_size=1, stride=1, padding=0, bias=False))
layers.append(nn.BatchNorm2d(out_channels))
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
return self.conv(x)
- 1
在InvertedResidual类中,expand_ratio表示升维的比例。根据stride和in_channels与out_channels的关系确定是否使用残差连接。在forward方法中,如果满足残差连接条件,则将输入与卷积后的结果相加,否则直接返回卷积结果。
MobileNet v2 的整体架构就是由多个这样的倒置残差结构和一些其他层(如初始卷积层、最终的平均池化层和全连接层等)组成。
五、MobileNet 在移动设备上的图像识别应用
(一)移动设备图像分类任务
在智能手机上的应用:
许多智能手机的相机应用都集成了基于 MobileNet 的图像分类功能。例如,当用户拍摄一张照片后,应用可以实时识别照片中的物体,如识别出拍摄的是一只猫、一辆汽车或者一朵花等,并为用户提供相关的信息或建议。这不仅增加了用户体验的趣味性,还可以用于一些实用的场景,如拍照购物(识别商品并提供购买链接)、拍照识别植物(提供植物的名称和相关知识)等。
以下是一个简单的示例代码,模拟在智能手机上使用 MobileNet v2 进行图像分类(假设已经有了预处理后的图像张量image_tensor和加载好的 MobileNet v2 模型model):
import torch
# 对图像进行预处理(这里假设已经完成了预处理)
# 使用模型进行预测
outputs = model(image_tensor)
_, predicted = torch.max(outputs, 1)
class_index = predicted.item()
# 根据类别索引获取类别名称(这里假设已经有了类别名称列表`class_names`)
class_name = class_names[class_index]
print(f"识别结果:{class_name}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在智能穿戴设备上的应用:
对于一些智能手表、智能眼镜等穿戴设备,由于其计算资源更为有限,MobileNet 的轻量级特性使其成为理想的选择。例如,智能眼镜可以通过摄像头实时捕捉用户视野中的图像,然后使用 MobileNet 进行快速的物体识别,为用户提供实时的信息提示。比如,当用户看到一个不认识的地标建筑时,智能眼镜可以快速识别并显示该建筑的名称和相关介绍。
然而,在智能穿戴设备上部署 MobileNet 也面临一些挑战,如设备的电池续航能力有限,需要对模型进行进一步的优化和量化,以降低功耗。同时,由于穿戴设备的屏幕较小,需要设计简洁明了的用户界面来展示识别结果,确保用户能够方便地获取信息。
(二)移动设备目标检测任务
与目标检测框架结合:
MobileNet 可以作为目标检测框架(如 SSD、YOLO 等)的骨干网络(Backbone Network),用于提取图像特征。例如,在 SSD(Single Shot MultiBox Detector)中,将 MobileNet 替换原来的骨干网络,可以大大减少模型的计算量和参数量,使其能够在移动设备上实时运行目标检测任务。
以下是一个使用 MobileNet v2 作为骨干网络的简化 SSD 模型示例(仅展示部分关键代码):
import torch
import torch.nn as nn
class SSDWithMobileNetV2(nn.Module):
def __init__(self, num_classes):
super(SSDWithMobileNetV2, self).__init__()
# 加载MobileNet v2作为骨干网络
self.backbone = MobileNetV2(width_mult=1.0)
# 定义额外的卷积层用于目标检测(这里省略具体实现)
self.extra_layers = nn.ModuleList()
# 定义检测头(这里省略具体实现)
self.detection_heads = nn.ModuleList()
def forward(self, x):
# 通过骨干网络提取特征
features = self.backbone(x)
# 通过额外的卷积层进一步提取特征
for layer in self.extra_layers:
x = layer(x)
features.append(x)
# 通过检测头进行目标检测(这里省略具体实现)
detections = []
for head in self.detection_heads:
detection = head(features)
detections.append(detection)
return detections
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在这个示例中,SSDWithMobileNetV2类继承自nn.Module,在__init__方法中初始化了 MobileNet v2 骨干网络、额外的卷积层和检测头。forward方法中,首先通过骨干网络提取特征,然后通过额外的卷积层进一步丰富特征,最后通过检测头进行目标检测,输出
评论记录:
回复评论: