配置
这里是使用 root 配置,如果你想用其他模式,那么看看文档 Installing the NVIDIA Container Toolkit - Nvidia Docs
安装好需要配置一下:
sudo nvidia-ctk runtime configure --runtime=docker
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
然后重启一下 Docker 服务:
sudo systemctl restart docker
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
好了,现在就做好所有的前置准备了。
部署 Ollama 到 GPU 上
需要注意在下面的步骤之前,要确定当前主机系统的 Ollama 已经关闭了,不然端口会显示占用,你如果需要同时使用,那么换个端口号,后面代码中也要进行相应的修改。
首先看看有没有后台运行:
$ ps -A |grep ollama
1321 ? 00:02:50 ollama
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
发现还在,那么关闭它:
sudo kill 1321
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
此时,使用下面的命令可以很轻松的实现部署:
docker run -d --gpus=all -v ./ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
这个命令的意思是:
--gpus=all使用所有的 GPU。-v ./ollama:/root/.ollama把当前目录下的ollama目录加载到容器的/root/.ollama,这样可以实现一些文件的共享,比如 Llama3.2-Vision 需要使用的图片。
这里说明一下为什么选择/root/.ollama,因为这个是 Ollama 模型的存放处,这样如果删除重装 Docker 容器之后,不用重新下载容器。
-p 11434:11434,把容器的端口11434和系统的端口11434对应起来。11434 是 Ollama 默认使用的端口号,官方示例也用的这个。--name ollama是这个容器的名称为ollama。ollama/ollama是映像(image)的名称。
使用下面的命令进入容器:
sudo docker exec -it ollama /bin/bash
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
进入容器后,直接可以使用ollama,不用再次安装。这里使用 Llama3.1 8B 的:
ollama run llama3.1 --verbose
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
--verbose选项可以让你看到生成速度。
然后就会看到下载模型,等一会就进入 Ollama 了:
root@b82bf49334f9:/
pulling manifest
pulling 667b0c1932bc... 100% ▕███████████████████████████████████████████████████████████████▏ 4.9 GB
pulling 948af2743fc7... 100% ▕███████████████████████████████████████████████████████████████▏ 1.5 KB
pulling 0ba8f0e314b4... 100% ▕███████████████████████████████████████████████████████████████▏ 12 KB
pulling 56bb8bd477a5... 100% ▕███████████████████████████████████████████████████████████████▏ 96 B
pulling 455f34728c9b... 100% ▕███████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>> 你好,请介绍一下你自己
大家好!我是 LLaMA,一个由 Meta 研发的语境理解和生成模型。我的主要功能是理解自然语言并根据上下文生成相关响应或内容。
total duration: 841.833803ms
load duration: 39.937882ms
prompt eval count: 17 token(s)
prompt eval duration: 5ms
prompt eval rate: 3400.00 tokens/s
eval count: 42 token(s)
eval duration: 795ms
eval rate: 52.83 tokens/s
>>> 你可以给我讲个故事吗
当然!这里有一个故事:
有一只小猴子名叫李莫,住在一个美丽的雨林里。他非常好奇,一天到晚都在探索周围的世界。有一天,他迷路了,找不到回家的路。
李莫沿着河流行走,希望能找到熟悉的地方。但是,无论他走多远,都不能见到熟悉的树木和花草。他开始感到害怕和孤独。
就在这时,他遇到了一个聪明的鸟儿。鸟儿问李莫:“你在哪里?你想去哪里?”李莫告诉了鸟儿自己的情况,鸟儿笑着说:“我知道这里的路
,你跟我走就可以找到回家的路。”
李莫和鸟儿一起行走,他们聊天、玩耍,这让小猴子觉得很开心。他慢慢地放下了担忧,感受到鸟儿的帮助和陪伴。
最后,他们来到一个熟悉的地方,小猴子看到家里熟悉的树木和花草,他高兴地冲向家门,鸟儿也跟着他一起欢笑。从那天起,李莫和鸟儿
成为好朋友,他们经常一起探索雨林里的秘密。
这个故事告诉我们,即使在迷路时,我们也可以寻找帮助和陪伴,而不是孤独地面对困难。
total duration: 6.86419438s
load duration: 35.787939ms
prompt eval count: 75 token(s)
prompt eval duration: 9ms
prompt eval rate: 8333.33 tokens/s
eval count: 306 token(s)
eval duration: 5.993s
eval rate: 51.06 tokens/s
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> class="hide-preCode-box">
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
在这种情况下不用担心性能损耗,因为 Docker 的实现模式和常规说的虚拟机不太一样,它其实就是基于主机系统的进行的。下面是我跑模型的时候nvidia-smi显示的的信息(我不记得是跑哪个模型的了),可以看到利用率还是不错的,功耗快满了:
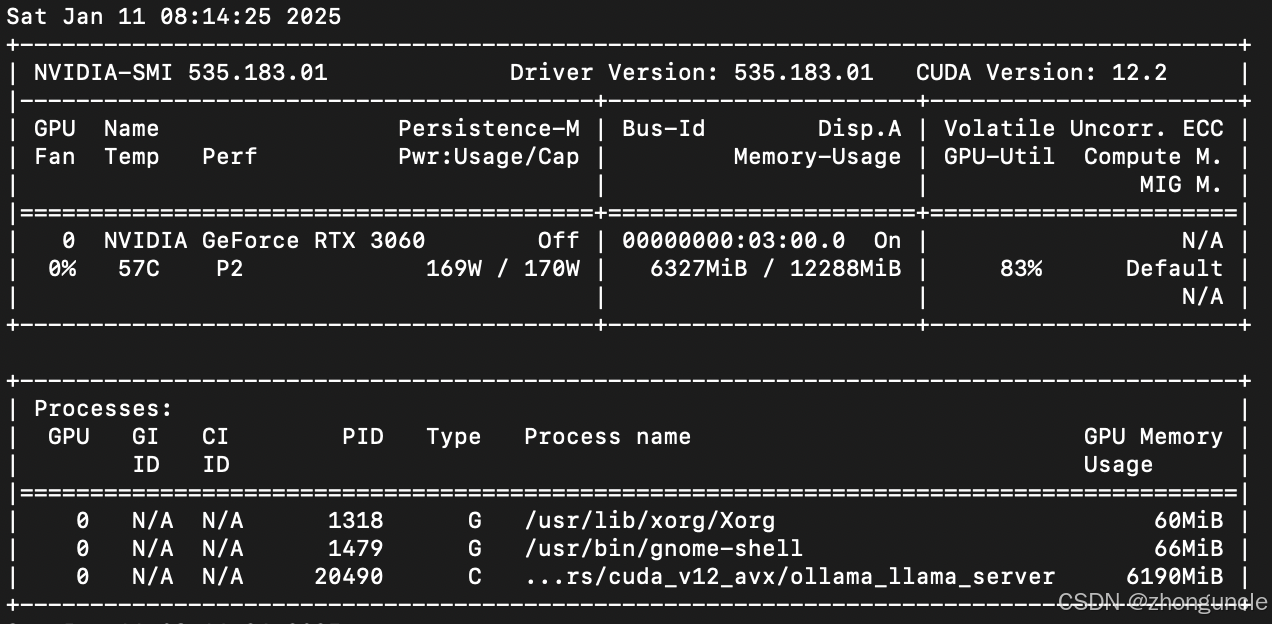
如何在主机系统上和容器内的 Ollama 沟通使用,这个我想放在另一篇博客中。因为我在使用 Llama 3.2-Vision 的时候需要传递图片,这个例子更加全面,就不在这里说了。
再次使用
关机之后,如果想再次使用容器,那么需要换一个命令启动。如果你熟悉 Docker,这点你应该很清楚。不过由于 Ollama 是一个服务,会随开机启动,所以你需要先再次终止进程:
$ ps -A | grep ollama
2060 ? 00:00:18 ollama
$ sudo kill 2060
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
然后启动前面创建的容器ollama:
docker start ollama
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
需要注意不要用docker run,不然会显示Unable to find image 'ollama:latest' locally。
希望能帮到有需要的人~
参考资料
How to deploy the llama3 large model in CPU and GPU environments with Ollama - Gen. David L.:我是在这篇文章知道要用容器的。
Ollama is now available as an official Docker image - Ollama:Ollama 官方介绍容器映像的时候,说了 Linux 要使用 GPU 必须用容器,macOS 是反过来的,要用 GPU 必须是独立程序。
https://hub.docker.com/r/ollama/ollama - DockerHub:Ollama Docker 官方映像的界面。
data-report-view="{"mod":"1585297308_001","spm":"1001.2101.3001.6548","dest":"https://blog.csdn.net/qq_33919450/article/details/145069806","extend1":"pc","ab":"new"}">>



 微信公众号
微信公众号


评论记录:
回复评论: