
介绍
Faster R-CNN 是一种用于目标检测的深度学习模型,它在精度和速度上取得了良好的平衡。该模型由 Ross Girshick 等人在 2015 年提出,并且是 R-CNN 系列(包括 Fast R-CNN)的一个重要改进版本。Faster R-CNN 的主要贡献在于引入了区域提议网络(Region Proposal Network, RPN),使得整个系统可以端到端地进行训练,而不需要像之前的方法那样依赖于外部的区域提议算法。同样使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及COCO竞赛中获得多个项目的第一名。

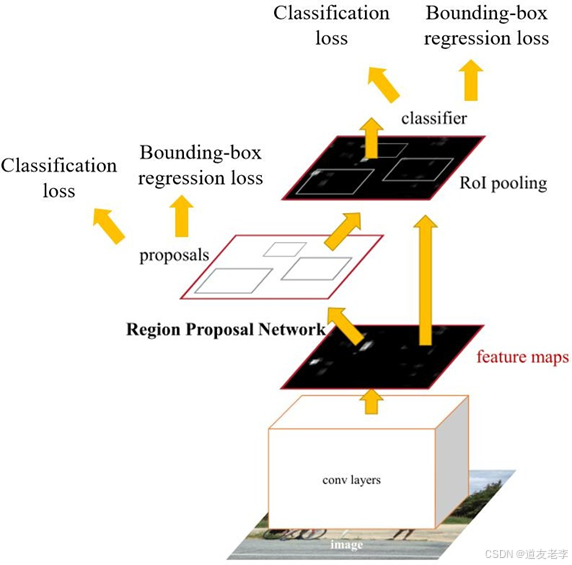
Faster R-CNN 的结构
Faster R-CNN 主要包含以下几个部分:
1.基础网络(Backbone Network)
- 使用预训练的卷积神经网络(如 VGG、ResNet 等)作为特征提取器。这个网络会生成一个高维特征图,用来捕捉输入图像中的不同层次的特征。
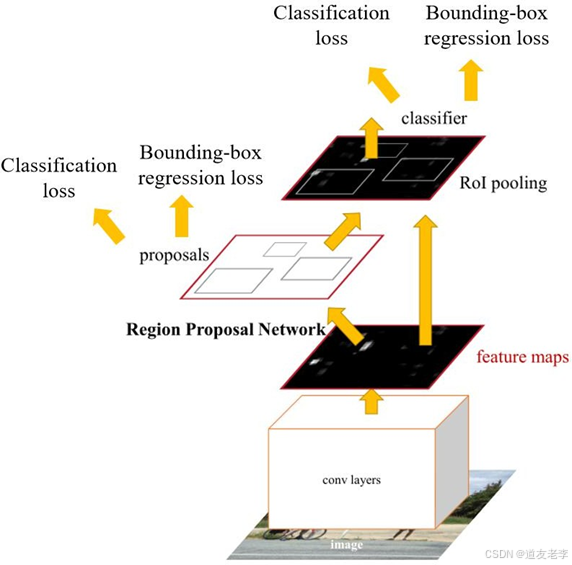
2.区域提议网络(RPN, Region Proposal Network)
- RPN 是 Faster R-CNN 的关键创新点之一。它直接从基础网络生成的特征图中产生候选区域(Region Proposals)。RPN 包含若干个小型卷积层,每个位置都对应一组锚框(Anchors),这些锚框具有不同的尺度和比例。对于每一个锚框,RPN 会预测两个值:一个是对象得分(即该位置是否包含一个对象),另一个是边界框回归参数(用于调整锚框的位置以更好地匹配真实对象)。
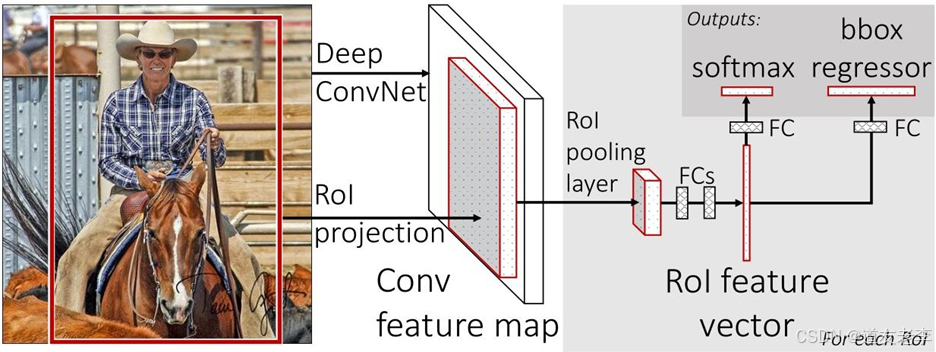
3.ROI Pooling 层
- 为了处理来自 RPN 的各种尺寸的候选区域,Faster R-CNN 使用 ROI Pooling(Region of Interest Pooling)层将它们统一成固定大小的特征向量。这一步骤确保了后续全连接层能够接收相同形状的输入。
4.分类与回归分支
- 经过 ROI Pooling 后,特征被送入两个并行的全连接层:一个负责对候选区域进行类别分类(Classify the object categories),另一个则进一步优化候选区域的坐标(Refine the bounding box coordinates)。这两个任务共同决定了最终的目标检测结果。
训练过程
- 多任务损失函数:Faster R-CNN 的训练涉及到多个子任务,因此采用了多任务损失函数。具体来说,总损失是由分类损失(通常是交叉熵损失 Cross Entropy Loss)和回归损失(通常采用平滑 L1 损失 Smooth L1 Loss)组成。其中,分类损失用于训练 RPN 和分类分支;回归损失则用于优化 RPN 提出的边界框以及最终输出的边界框。
- 端到端训练:通过共享的基础网络,Faster R-CNN 实现了从原始图像到最终检测结果的端到端训练。这意味着所有组件可以在同一个框架内同时优化,从而提高了整体性能。
应用优势 - 高效性:由于集成了 RPN,Faster R-CNN 不再需要额外的时间来生成区域提议,这大大加快了检测速度。
- 准确性:相比之前的 R-CNN 和 Fast R-CNN 方法,Faster R-CNN 在多种基准测试数据集上表现出更高的准确率。
- 灵活性:支持多种类型的 CNN 作为骨干网络,并且可以通过微调适应不同的应用场景。
缺点与局限性
1. 计算复杂度较高
- 多阶段处理:Faster R-CNN 包含多个阶段(如特征提取、区域提议生成、ROI Pooling 和分类/回归),这导致了相对较高的计算开销。虽然引入了 RPN 来加速区域提议的生成,但整个流程仍然比一些单阶段检测器(例如 YOLO 或 SSD)更耗时。
- 内存占用大:由于需要存储大量的中间特征图以及候选框信息,特别是在高分辨率图像上进行检测时,Faster R-CNN 对 GPU 内存的要求较高。
2. 训练难度较大
- 多任务联合优化:Faster R-CNN 同时优化 RPN 和检测网络,这意味着它涉及到多个损失函数之间的平衡问题。如果参数设置不当,可能会导致其中一个任务过拟合而另一个欠拟合。
- 预训练依赖性强:为了获得较好的初始化权重,通常需要使用在大规模数据集(如 ImageNet)上预训练的基础网络。对于特定领域或小样本情况下的应用,迁移学习的效果可能不如预期。
3. 对小物体检测效果有限
- 锚框设计限制:RPN 中的锚框是预先定义好的,它们的数量、尺度和比例都是固定的。当遇到非常小的目标或者形状奇特的对象时,现有的锚框可能无法很好地覆盖这些实例,从而影响检测精度。
- 下采样带来的信息丢失:随着卷积层的加深,特征图逐渐缩小,这可能导致小物体的信息在高层次特征中被过度压缩,进而难以准确检测到。
4. 背景误报较多
- 正负样本不平衡:在训练过程中,正样本(包含对象的区域)与负样本(背景区域)的数量往往存在很大差异。如果不加以处理,容易造成模型偏向于预测背景,产生较多的误报。
5. 部署挑战
- 硬件要求严格:由于其复杂的架构和较大的模型尺寸,Faster R-CNN 需要较强的计算资源来支持实时推理,这对于边缘设备或移动平台来说是一个不小的挑战。
- 延迟敏感的应用受限:对于那些对响应时间有严格要求的应用场景(如自动驾驶汽车中的即时决策系统),Faster R-CNN 的推理速度可能无法满足需求。
总之,Faster R-CNN 是现代目标检测领域的一个里程碑式的工作,它的设计思想和架构为后来的研究提供了宝贵的经验。
网络解析
算法流程
- Fast R-CNN算法流程可分为3个步骤:
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果

RPN网络
介绍
区域提议网络(Region Proposal Network, RPN)是 Faster R-CNN 架构中的一个重要组成部分,它负责生成高质量的候选框(即可能包含目标的区域),从而取代了传统的目标检测方法中使用的Selective Search等外部区域提议算法。RPN 的引入使得整个检测流程可以端到端地进行训练,并显著提高了检测速度和精度。
RPN 的工作原理
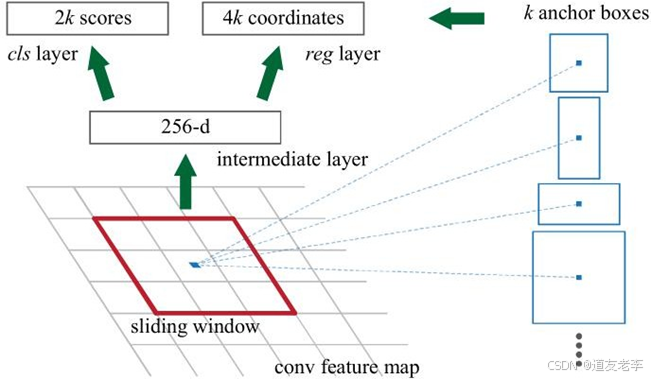
- 输入特征图:
RPN 接收来自基础网络(如 VGG、ResNet 等卷积神经网络)的最后一层或几层特征图作为输入。这些特征图已经包含了丰富的空间信息和语义信息。 - 滑动窗口与锚框:
在每个位置上,RPN 使用一个小的滑动窗口(通常是 3x3 卷积核)来扫描整个特征图。对于每一个滑动窗口的位置,预定义一组固定大小和比例的锚框(Anchors)。例如,在一个特定位置,可能会有 k 个不同尺度和长宽比的锚框。 - 输出预测:
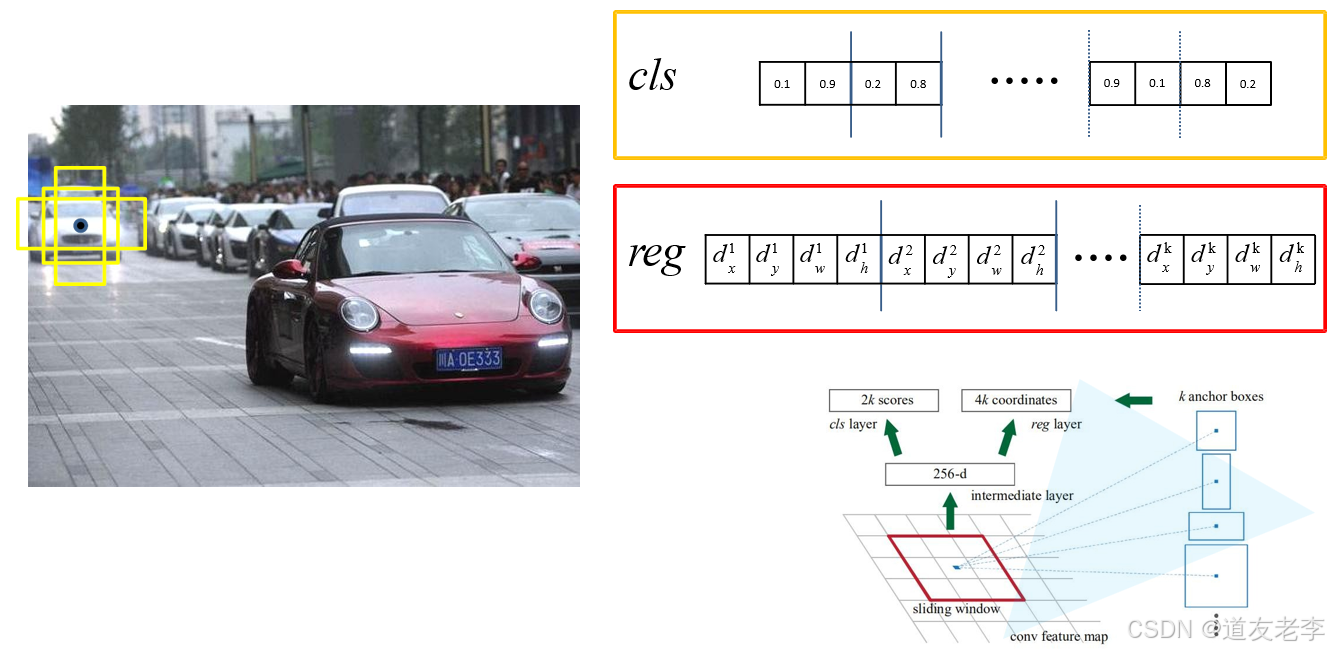
- 对于每一个锚框,RPN 会输出两个部分的结果:
- 对象得分(Objectness Score):表示该锚框是否包含一个目标的概率。这通常是一个二分类问题,用 sigmoid 函数将输出限制在 [0, 1] 区间内。
- 边界框回归参数(Bounding Box Regression Parameters):用于调整锚框的位置以更好地匹配真实的目标边界框。这包括四个值:中心坐标偏移量(Δx, Δy)和宽度高度缩放因子(Δw, Δh)。
- 对于每一个锚框,RPN 会输出两个部分的结果:
- 非极大值抑制(Non-Maximum Suppression, NMS):
为了减少冗余的提议区域,RPN 还会对所有候选框应用非极大值抑制,保留那些具有最高得分且不与其他高分框重叠太多的提议。
RPN 的损失函数
RPN 的训练涉及到两个主要任务:分类(区分前景和背景)和回归(优化边界框)。因此,它的总损失函数由两部分组成:
- 分类损失(Classification Loss):使用交叉熵损失(Cross Entropy Loss)衡量锚框是否正确地标记为前景或背景。
- 回归损失(Regression Loss):采用平滑 L1 损失(Smooth L1 Loss)来惩罚预测边界框与真实边界框之间的差异。只有正样本(即标记为前景的锚框)参与回归损失计算。
RPN 的训练过程
- 采样策略:由于正负样本数量不平衡,RPN 采用了在线硬例挖掘(Online Hard Example Mining, OHEM)或其他平衡采样方法,确保每次迭代时都有适当比例的正负样本参与训练。
- 共享特征提取器:RPN 和最终的分类/回归分支共享同一个基础网络,这意味着它们可以从相同的特征图中学习,减少了重复计算并促进了联合优化。
RPN 的优点
- 高效性:相比于传统的区域提议算法,RPN 可以快速生成大量高质量的候选框,而且可以直接嵌入到深度学习框架中,实现端到端训练。
- 灵活性:RPN 不依赖于具体的物体类别,它可以为任何类型的对象生成提议,因此适用于多类目标检测任务。
RPN 的局限性
- 锚框设计:虽然 RPN 提供了一种灵活的方式来处理不同尺度和比例的对象,但对于某些极端形状或非常小的目标,预定义的锚框可能不够准确。
- 计算资源需求:尽管 RPN 提高了效率,但它仍然增加了模型的复杂性和计算负担,特别是在处理高分辨率图像时。
候选框
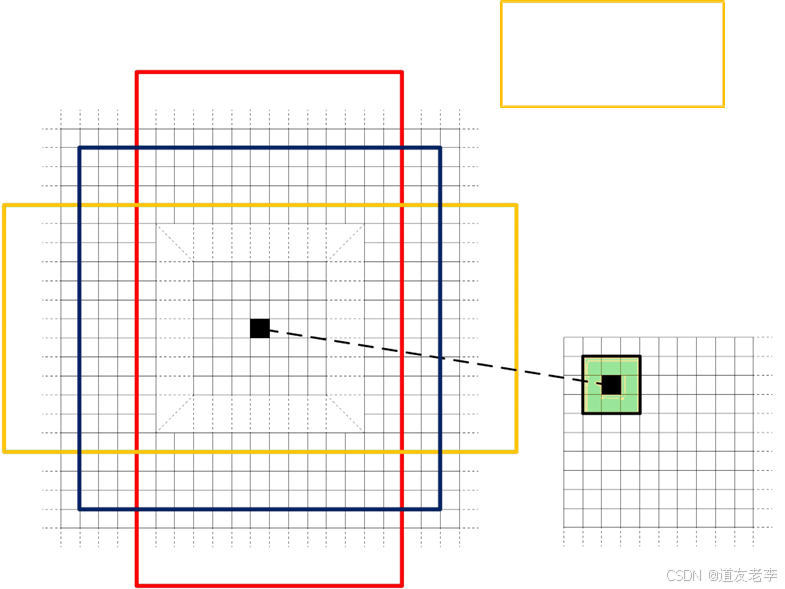

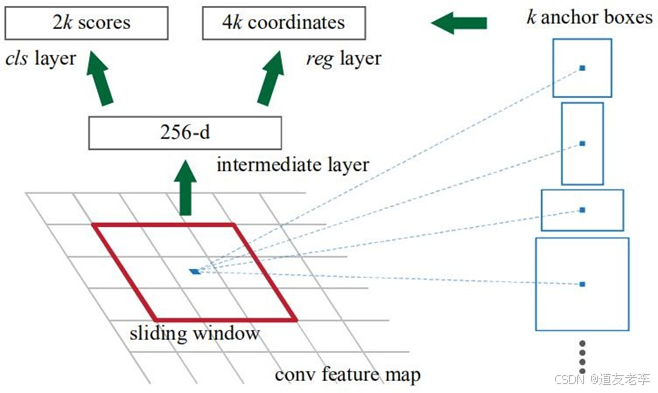
对于特征图上的每个3x3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出k个anchorboxes(注意和proposal的差异)。
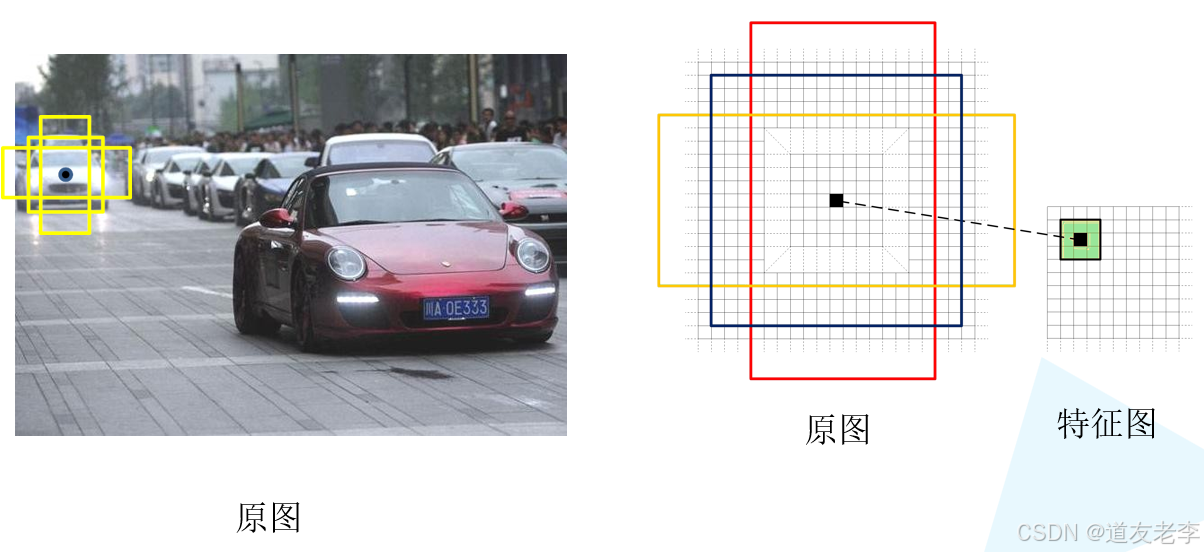
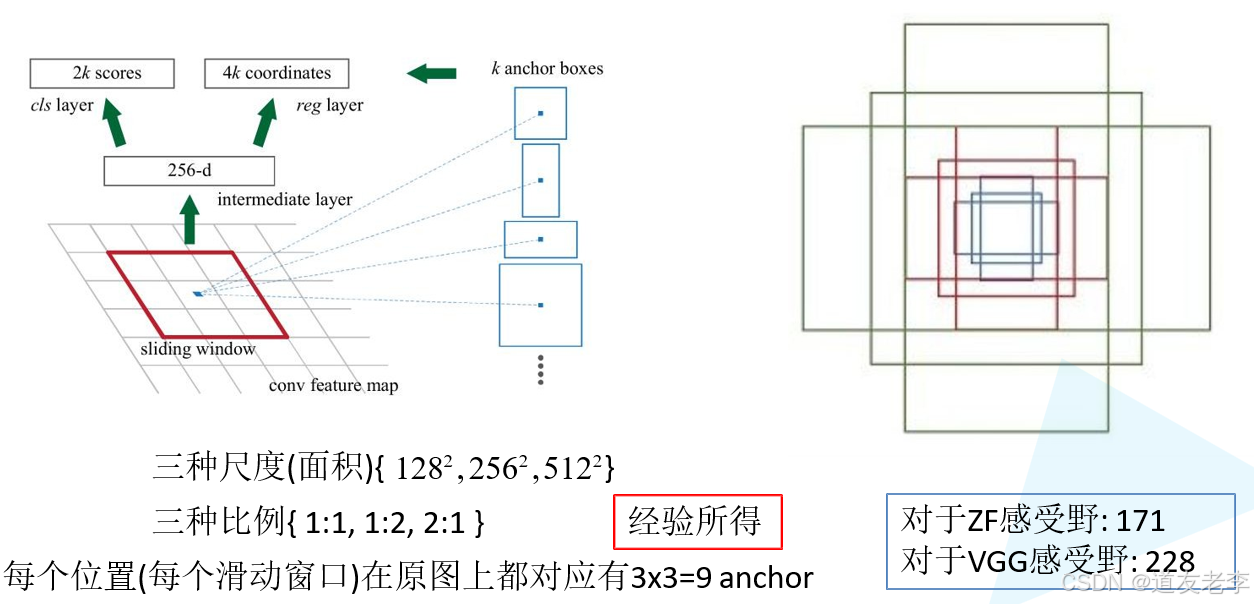
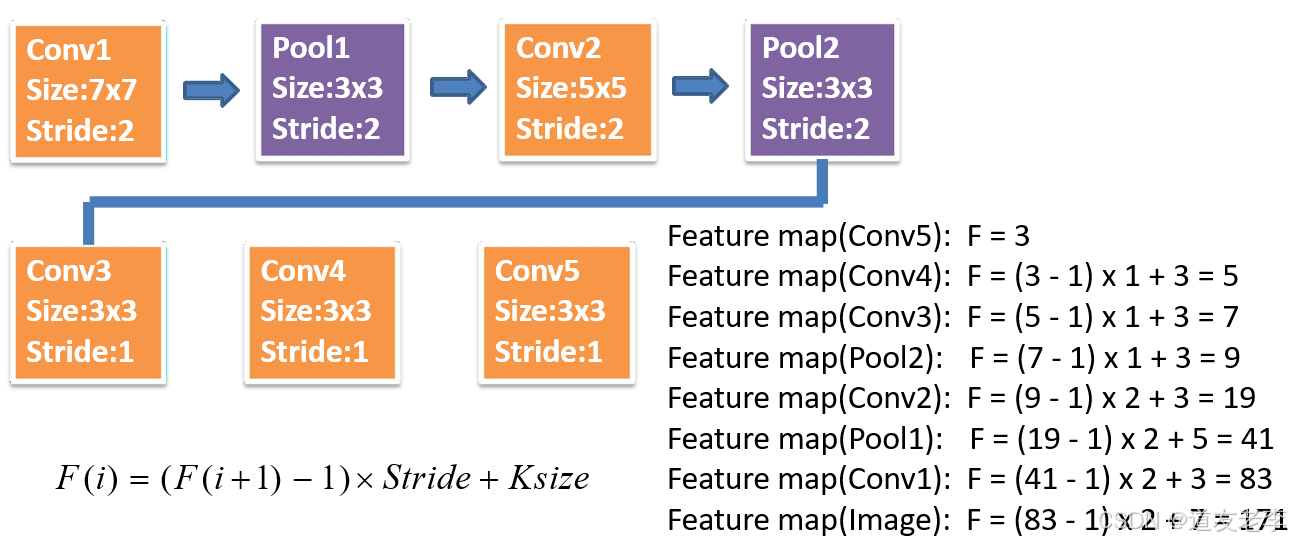
计算FasterRCNN中ZF网络featuremap中3x3滑动窗口在原图中感受野的大小。
三种尺度(面积):{ 128² , 256²,512² }
三种比例{ 1:1, 1:2, 2:1 }
每个位置在原图上都对应有3x3=9 anchor
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU 设为0.7,这样每张图片只剩2k个候选框。
Faster R-CNN的训练
直接采用RPNLoss+FastR-CNNLoss的联合训练方法,原论文中采用分别训练RPN以及FastR-CNN的方法。
- 利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数;
- 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN 网络生成的目标建议框去训练Fast R-CNN网络参数。
- 固定利用Fast R-CNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
- 同样保持固定前置卷积网络层参数,去微调Fast R-CNN网络的全连接层参数。最后RPN网络与Fast R-CNN网络共享前置卷积网络层参数,构成一个统一网络。
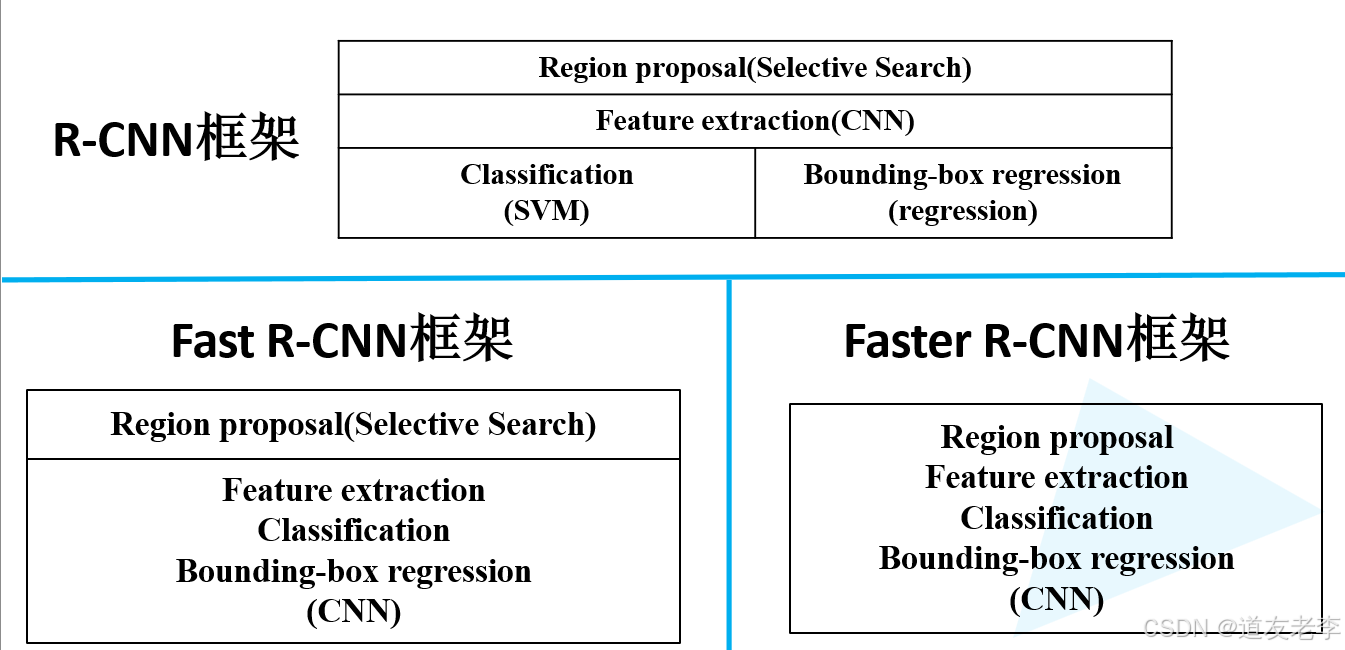
三种网络结构比较
评论记录:
回复评论: