
介绍
目标检测(Object Detection)是计算机视觉领域中的一个关键任务,旨在识别图像或视频中特定类别的对象,并给出每个对象的位置(通常以边界框的形式)。它结合了分类和定位两个方面的能力,不仅需要确定图像中存在哪些对象,还需要准确指出它们的位置。
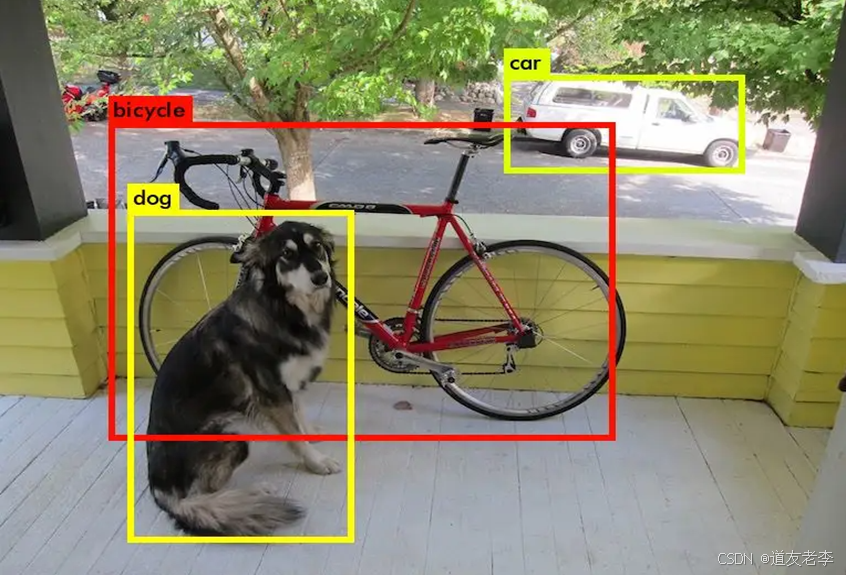
分类网络是基础,必须要熟练掌握。
发展历程
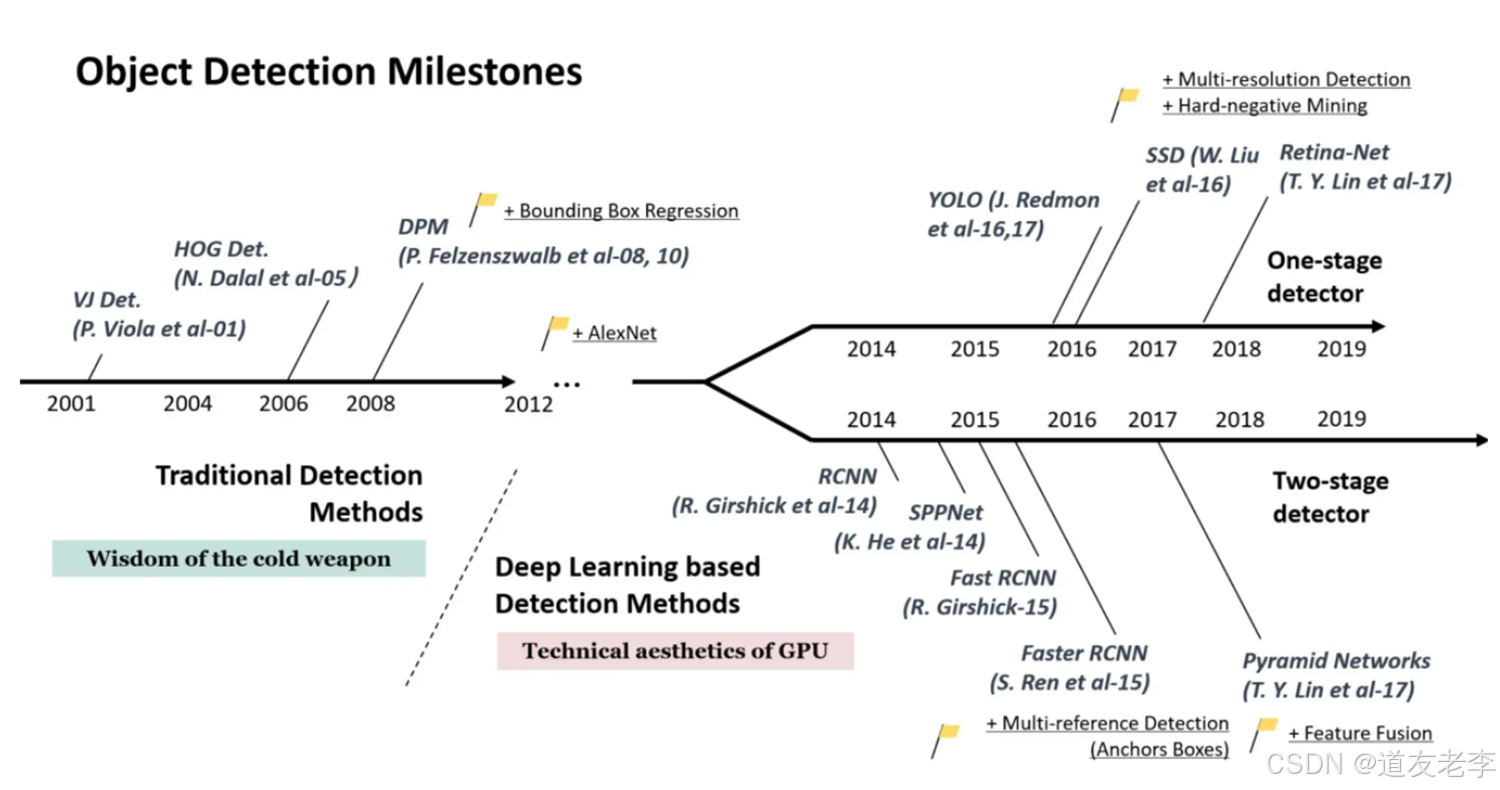
TWO-Stage
- 通过专门模块生成候选框(RPN)去寻找前景以及调整边界框.
- 基于之前生成的候选框进行进一步分类以及调整边界框.
- 优点:检测准确.
- 代表算法:Faster-RCNN
One-Stage
- 基于anchors直接进行分类以及调整边界框.
- 优点:检测速度快.
- 代表算法:YOLO系列算法.
目标检测的基本要素
- 分类:确定图像中出现的对象类别。
- 定位:为每个检测到的对象提供精确的边界框坐标。
传统方法与深度学习方法
传统方法
在深度学习兴起之前,目标检测主要依赖于手工设计的特征(如HOG特征、SIFT等)以及滑动窗口策略。这类方法通常效率较低且效果有限。
深度学习方法
近年来,随着卷积神经网络(CNNs)的发展,基于深度学习的目标检测算法取得了显著的进步。这些方法可以分为两大类:
- 两阶段检测器(Two-stage Detectors)
- R-CNN系列:包括R-CNN, Fast R-CNN, Faster R-CNN等。这类方法首先生成候选区域(Region Proposals),然后对每个候选区域进行分类和边界框回归。
- 特点:精度较高,但计算成本较大,速度相对较慢。
- 单阶段检测器(One-stage Detectors)
- YOLO (You Only Look Once):将整个输入图像划分为网格,并直接预测每个网格单元格内的物体类别及其边界框。
- SSD (Single Shot MultiBox Detector):使用多尺度特征图来检测不同大小的对象,并通过默认框(Default Boxes)机制提高小物体检测性能。
- 特点:速度快,适合实时应用,但在小物体检测和高精度要求的任务上可能不如两阶段检测器。
现代目标检测框架的关键组件
- 骨干网络(Backbone Network):
提取输入图像的特征表示。常用的骨干网络包括VGG, ResNet, MobileNet等。 - 颈部结构(Neck):
对骨干网络提取的特征进行进一步处理,例如FPN(Feature Pyramid Networks)用于构建多尺度特征金字塔,有助于提升小物体检测效果。 - 头部结构(Head):
负责具体的任务,如分类和边界框回归。根据是否采用两阶段架构,头部结构的设计会有所不同。
损失函数(Loss Function): - 包括分类损失(Class Loss)和边界框回归损失(Box Regression Loss)。常见的分类损失有交叉熵损失(Cross-Entropy Loss),而边界框回归损失则常用平滑L1损失(Smooth L1 Loss)。
- 后处理(Post-processing):
- 非极大值抑制(Non-Maximum Suppression, NMS)用于去除冗余的检测结果,保留最高置信度的边界框。
应用场景
目标检测技术广泛应用于多个领域,包括但不限于:
- 自动驾驶:识别行人、车辆和其他障碍物。
- 安防监控:检测异常行为或入侵者。
- 医疗影像分析:辅助医生识别病变区域。
零售行业:自动结账系统中的商品识别。
无人机和机器人导航:环境感知与避障。
社交媒体内容审核:过滤不适当的内容。
总之,目标检测作为计算机视觉的核心任务之一,其研究和发展对于推动自动化系统理解和交互现实世界具有重要意义。随着硬件性能的提升和技术的进步,未来的目标检测算法有望变得更加高效、精准和多样化。
目标检测算法
1. R-CNN系列
R-CNN (Region-based Convolutional Neural Network)
- 工作流程:首先生成候选区域(Region Proposals),然后对每个候选区域进行特征提取和分类。
局限性:计算效率低,因为需要为每个候选区域单独提取特征。
Fast R-CNN
- 改进点:通过共享整个图像的卷积特征图,减少了重复计算;直接在全连接层上进行边界框回归和分类。
- 优势:显著提高了速度,但仍依赖于外部候选区域生成器。
Faster R-CNN
- 创新点:引入了区域建议网络(Region Proposal Network, RPN),实现了候选区域生成与检测一体化。
- 特点:两阶段方法,先生成候选区域再精确定位和分类,是目前最常用的目标检测框架之一。
Mask R-CNN
- 扩展功能:除了检测外还能进行实例分割,即不仅给出对象的位置还提供像素级别的掩码。
- 应用场景:适合需要精确位置信息的任务,如自动驾驶、医学影像分析等。
2. 单阶段检测器
YOLO (You Only Look Once):
- 版本演变:包括YOLOv1至YOLOv10等多个版本,性能不断提升。
- 特点:将目标检测视为一个回归问题,直接从整张图片预测出类别和边界框坐标。
- 优势:速度快,适用于实时应用;但早期版本对小物体检测效果不佳,后来版本有所改善。
SSD (Single Shot MultiBox Detector):
- 设计思路:采用多尺度特征图来捕捉不同大小的对象,并结合默认框机制提高检测精度。
- 特点:比YOLO更注重小物体检测,同时保持较高的检测速度。
RetinaNet:
- 解决的问题:针对单阶段检测器中存在的类别不平衡问题提出了Focal Loss损失函数。
- 特点:通过调整损失函数使得模型更加关注难例样本,从而提升了检测性能。
3. 其他新兴方法
CenterNet:
- 核心思想:基于关键点估计的方式来进行目标检测,将每个对象中心作为关键点进行定位,然后扩展成边界框。
- 特点:简化了检测流程,提供了较好的检测效果,尤其是在拥挤场景下。
DETR (Detection Transformer):
- 架构创新:首次将Transformer应用于目标检测任务,摒弃了传统的锚框(Anchor)概念。
- 特点:端到端的训练方式,具有良好的泛化能力和可解释性,但在初期版本中推理速度较慢。
评论记录:
回复评论: