
介绍
ResNet(残差网络,Residual Network)是由微软研究院的研究人员在2015年提出的一种深度卷积神经网络架构,它解决了训练非常深的网络时遇到的主要挑战之一——退化问题。随着网络深度增加,训练误差不再继续减小反而开始增加,这并不是由于过拟合引起的。ResNet通过引入“残差学习”框架来解决这个问题,极大地推动了深度学习的发展,并在多个计算机视觉任务中取得了优异的成绩。斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。(啥也别说了,就是NB)
残差块(Residual Block)
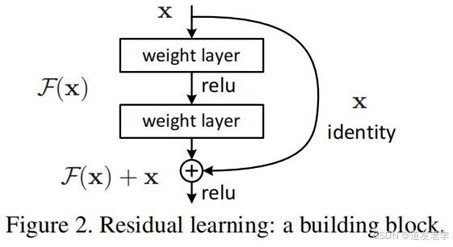
ResNet的核心创新是残差块(或称为跳跃连接、快捷连接)。每个残差块包含两个主要部分:
- 主路径:一系列卷积层、批归一化(Batch Normalization)层和ReLU激活函数。
- 跳跃连接(Shortcut Connection):直接将输入添加到输出上,形成所谓的残差学习。即如果一个残差块的输入为x,经过若干层变换后的输出为F(x),那么最终的输出就是H(x) = F(x) + x。这样做的好处是可以让网络更容易地学习恒等映射,从而缓解了深层网络训练中的梯度消失问题。
ResNet的特点
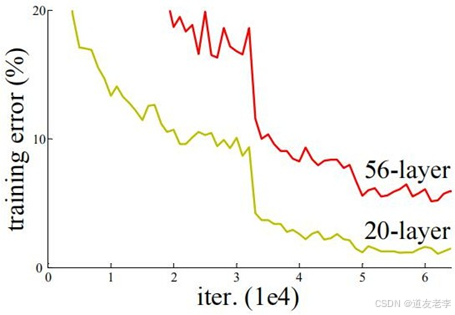
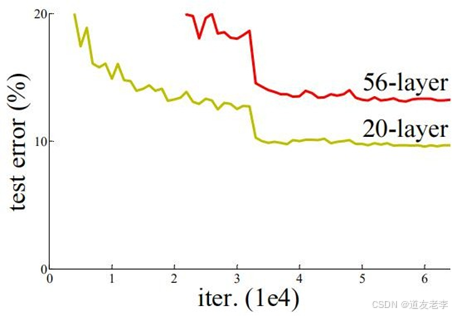
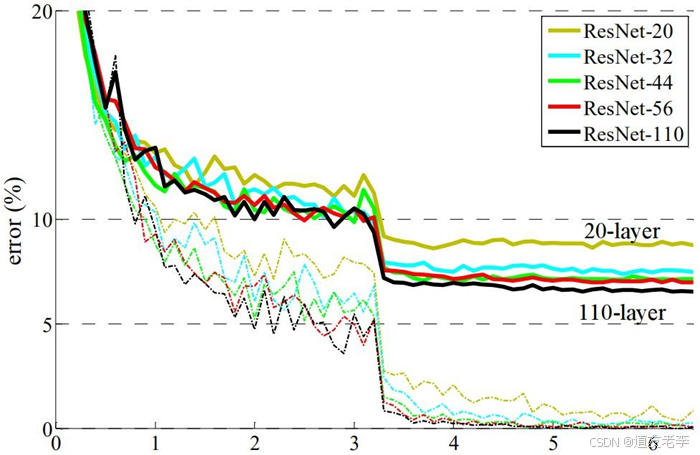
- 深度:ResNet可以非常深,原论文中展示了超过100层甚至1000多层的模型,这在当时是一个重大的突破。
- 跳跃连接:这些连接允许梯度在反向传播过程中更直接地流动,避免了传统深层网络中常见的梯度消失问题,使得更深的网络也能够有效地被训练。
- 简化优化:残差学习使得网络可以更好地收敛,即使在网络非常深的情况下也是如此。这是因为学习残差(即差异)比直接学习未经转换的映射要容易得多。
- 灵活性:ResNet的设计足够灵活,可以在不同的深度和宽度上进行调整,以适应不同的任务需求。
缺点
尽管ResNet(残差网络)在深度学习和计算机视觉领域取得了显著的成功,但它并非没有缺点或局限性。以下是ResNet的一些潜在缺点:
1. 参数量与计算成本
- 高参数量:随着网络深度的增加,ResNet的参数数量也会相应增长,这可能会导致模型体积庞大,尤其是在使用更深版本(如ResNet-152)时。
- 计算资源需求大:训练和推理过程中需要大量的计算资源,特别是在处理高分辨率图像或实时应用时,这对硬件提出了更高的要求。
2. 过拟合风险
- 复杂度增加:虽然跳跃连接有助于缓解梯度消失问题,但当网络变得非常深时,过多的参数可能导致过拟合现象,特别是在训练数据有限的情况下。
3. 模型解释性差
- 黑箱性质:如同大多数深度神经网络一样,ResNet作为一个高度复杂的非线性系统,其决策过程难以直观理解,给模型解释性和可解释性带来了挑战。
4. 训练时间长
- 收敛速度:尽管残差块的设计使得深层网络更容易训练,但对于极深的网络结构来说,训练到最佳性能仍然可能需要较长时间,尤其是如果没有适当的优化技巧或硬件支持。
5. 网络设计灵活性受限
- 固定结构:ResNet的基本构建单元是残差块,这种固定的模块化设计虽然简化了网络构建过程,但在某些特定任务中可能不够灵活,无法轻易适应所有类型的视觉任务。
6. 对小数据集的适应性
- 迁移学习依赖:对于小规模数据集,直接训练一个完整的ResNet模型可能是不切实际的,通常需要依赖预训练模型进行迁移学习。然而,即使在这种情况下,如何有效地调整预训练模型以适应新任务仍然是一个挑战。
7. 跳跃连接的限制
- 信息流瓶颈:尽管跳跃连接解决了梯度消失的问题,但它们也可能引入新的问题,比如在极端情况下,如果主路径上的变换过于简单或者恒等映射占据了主导地位,那么网络的有效表达能力可能会受到限制。
8. 内存占用
- 内存消耗:由于ResNet可以非常深,并且每一层都需要保存激活值用于反向传播,因此它在训练时会占用大量内存,这对于GPU显存有限的情况是一个重要考虑因素。
应用场景
ResNet及其变体(如ResNet-50, ResNet-101, ResNet-152等)广泛应用于各种计算机视觉任务中,包括但不限于:
- 图像分类:ResNet最初就是在ImageNet大规模视觉识别挑战赛中获得第一名而闻名,它在图像分类任务中表现出色。
- 目标检测:例如,在Faster R-CNN、Mask R-CNN等目标检测框架中,ResNet作为骨干网络提取特征图。
- 语义分割:ResNet也被用于语义分割任务,如DeepLab系列模型中。
- 迁移学习:预训练好的ResNet模型非常适合用来进行迁移学习,特别是在处理小规模数据集时,可以通过微调获得不错的效果。
- 视频分析:对于视频帧间的特征提取,ResNet同样表现出色,可以结合时间维度信息来进行动作分类或其他视频分析任务。
总之,ResNet通过其独特的残差学习机制,不仅大大提升了深度网络的能力边界,还成为了许多后续研究和应用的基础。它的出现标志着深度学习领域的一个重要里程碑,并持续影响着该领域的进步和发展。
ResNet详解


网络中的亮点
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch Normalization加速训练(丢弃dropout)
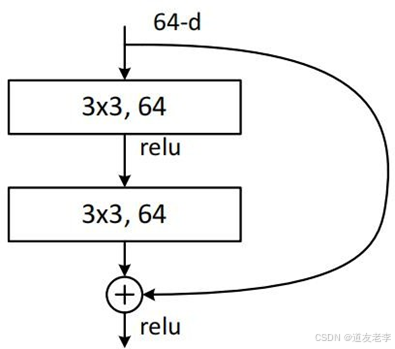
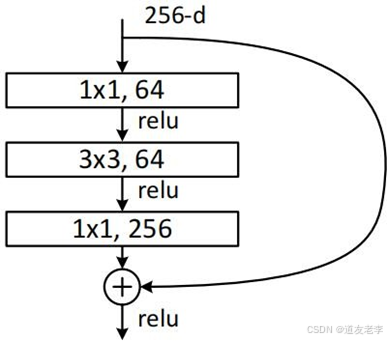
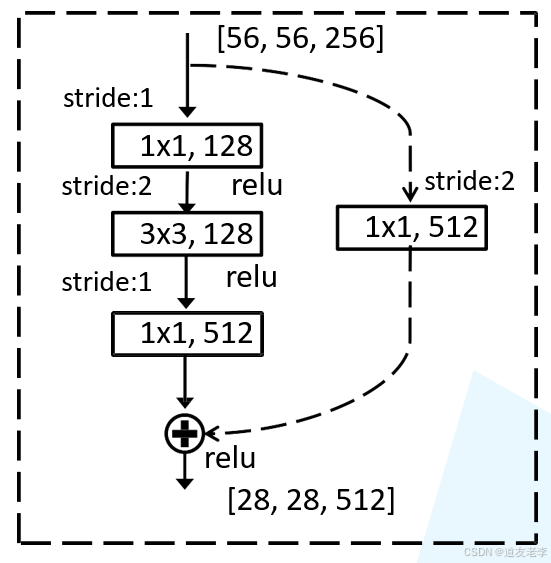
residual模块
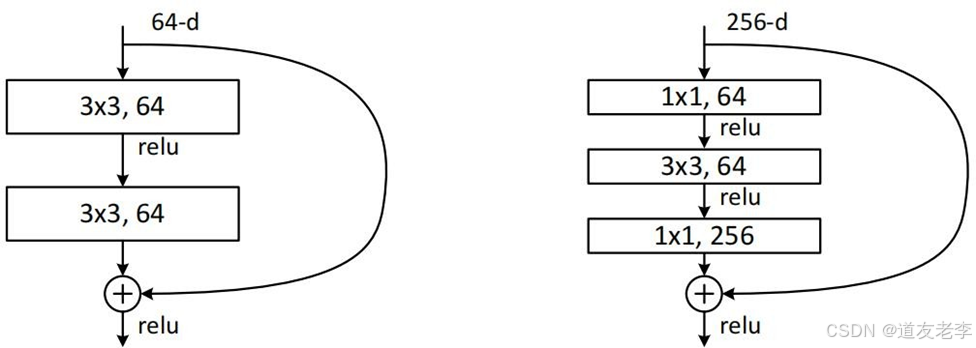
1x1的卷积核用来降维和升维
3 x 3 x 256 x 256 + 3 x 3 x 256 x 256 = 1,179,648
1 x 1 x 256 x 64 + 3 x 3 x 64 x 64 +1 x 1 x 64 x 256 = 69,632
Batch Normalization
Batch Normalization的目的是使我们的一批(Batch)featuremap满足均值为0,方差为1的分布规律。
Batch Normalization(批归一化)是ResNet架构中的一个重要组成部分,它对提升训练效率和模型性能起到了关键作用。在ResNet中,Batch Normalization通常位于卷积层之后、非线性激活函数(如ReLU)之前。
Batch Normalization的作用
- 加速收敛:
通过减少内部协变量偏移(Internal Covariate Shift),即每一层输入分布的变化,Batch Normalization使得网络能够更快地收敛。这允许使用更高的学习率进行训练,而不必担心数值不稳定的问题。 - 正则化效果:
Batch Normalization引入了一种隐式的正则化效应,因为每批次的数据都会被标准化处理。这种随机性有助于防止过拟合,特别是在小批量(mini-batch)训练时。 - 简化超参数调优:
它减少了对其他形式的正则化(如Dropout或权重衰减)的依赖,并且可以在一定程度上缓解对初始化策略的选择敏感度。 - 允许使用更高学习率:
由于Batch Normalization稳定了网络的训练过程,可以采用较大的学习率而不会导致梯度爆炸或消失问题。
在ResNet中的具体实现
- 位置:在ResNet中,Batch Normalization通常紧跟在每个卷积操作之后。对于一个标准的残差块,其结构通常是 Conv -> BN -> ReLU。
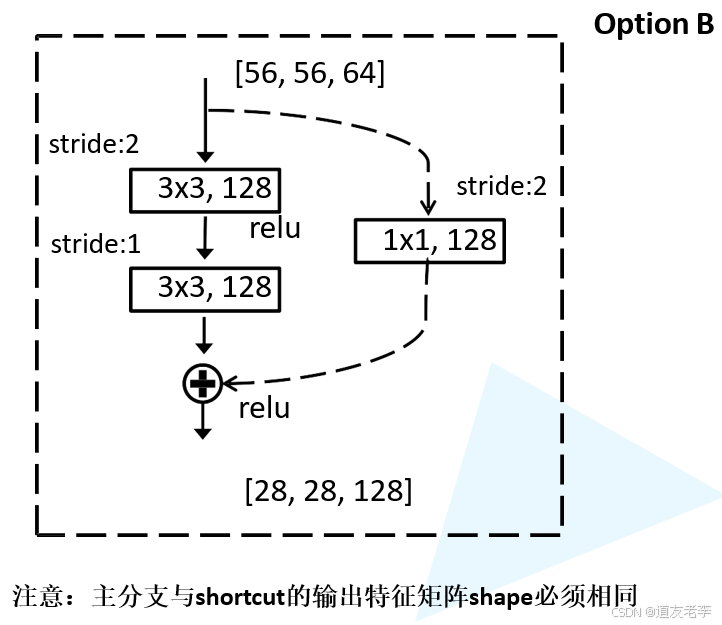
- 跳跃连接前后的BN层:在ResNet的残差块设计中,主路径上的最后一个卷积层后面会有一个BN层,然后才将结果与跳跃连接相加。这一设计确保了在添加之前两个分支的数据都被标准化,从而保持一致性。
- 处理不同维度的跳跃连接:当跳跃连接需要改变特征图的尺寸或通道数时(例如通过步长为2的卷积或1x1卷积来调整维度),ResNet也会在这类跳跃连接上应用Batch Normalization,以保证输入输出的一致性和稳定性。
Batch Normalization的工作原理
Batch Normalization通过对每一批次的数据进行标准化处理,使每个特征具有零均值和单位方差。具体来说,它计算每个特征在当前批次内的均值和方差,然后利用这些统计量对特征进行缩放和平移(通过可学习的参数γ和β)。公式如下:
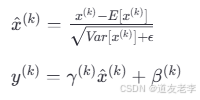
训练与推理阶段的区别
- 训练阶段:在每次迭代中,Batch Normalization根据当前批次的数据动态计算均值和方差。
- 推理阶段:为了避免使用单一样本的统计信息,通常会使用训练期间累积的移动平均值来代替批次统计信息。这样可以确保推理时的稳定性。
总之,Batch Normalization在ResNet中不仅增强了模型的表现力,还提高了训练效率,成为现代深度神经网络不可或缺的一部分。

评论记录:
回复评论: