
1.3 浅层神经网络
学习目标
- 目标
- 知道浅层神经网络的前向计算过程
- 知道选择激活函数的原因
- 说明浅层网络的反向传播推导过程
- 应用
- 应用完成一个浅层神经网络结构进行分类
1.3.1 浅层神经网络表示
之前已经说过神经网络的结构了,在这不重复叙述。假设我们有如下结构的网络
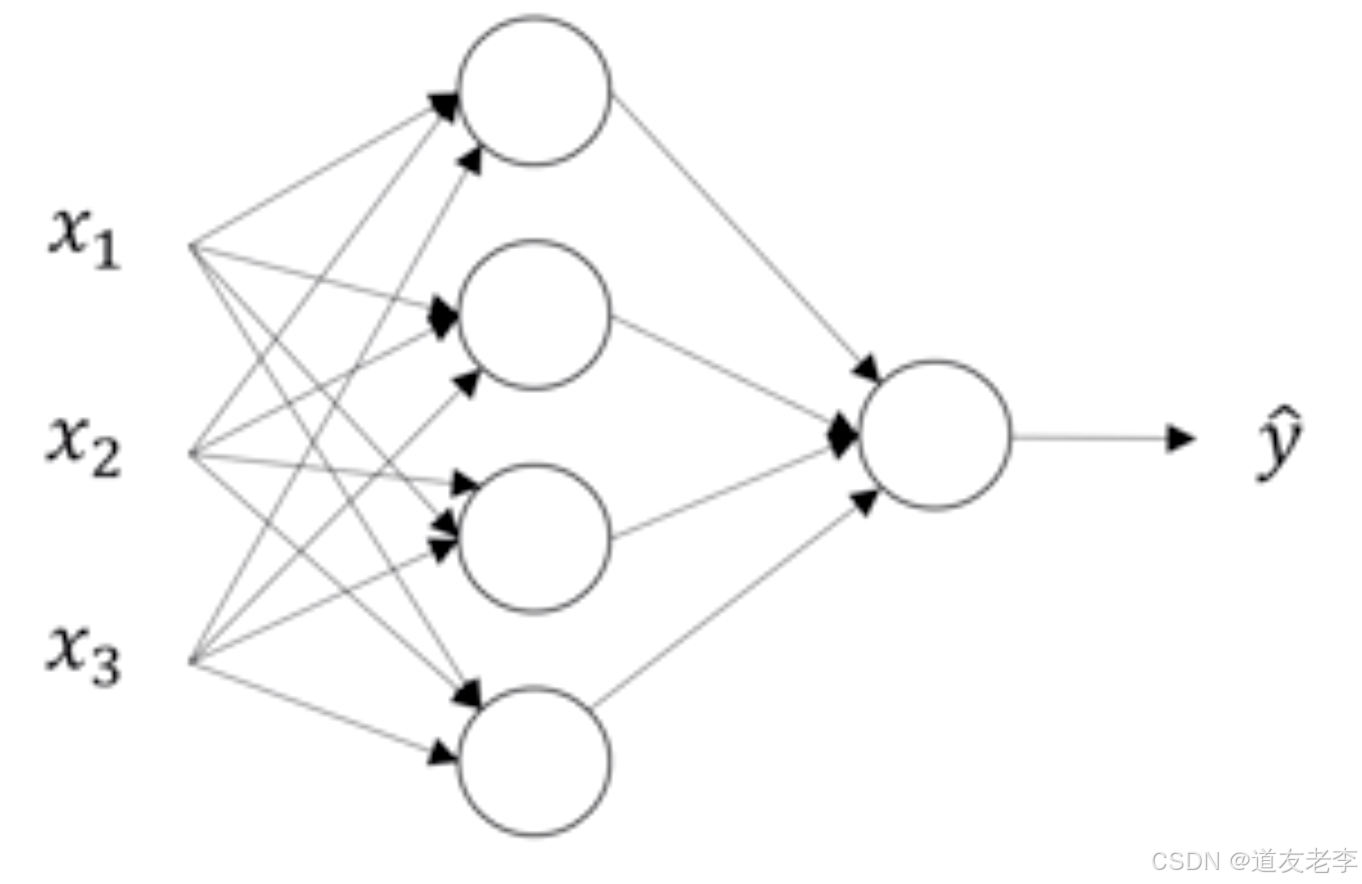
对于这个网络我们建立一个简单的图示?我们对第一个隐藏层记为[1],输出层为[2]。如下图
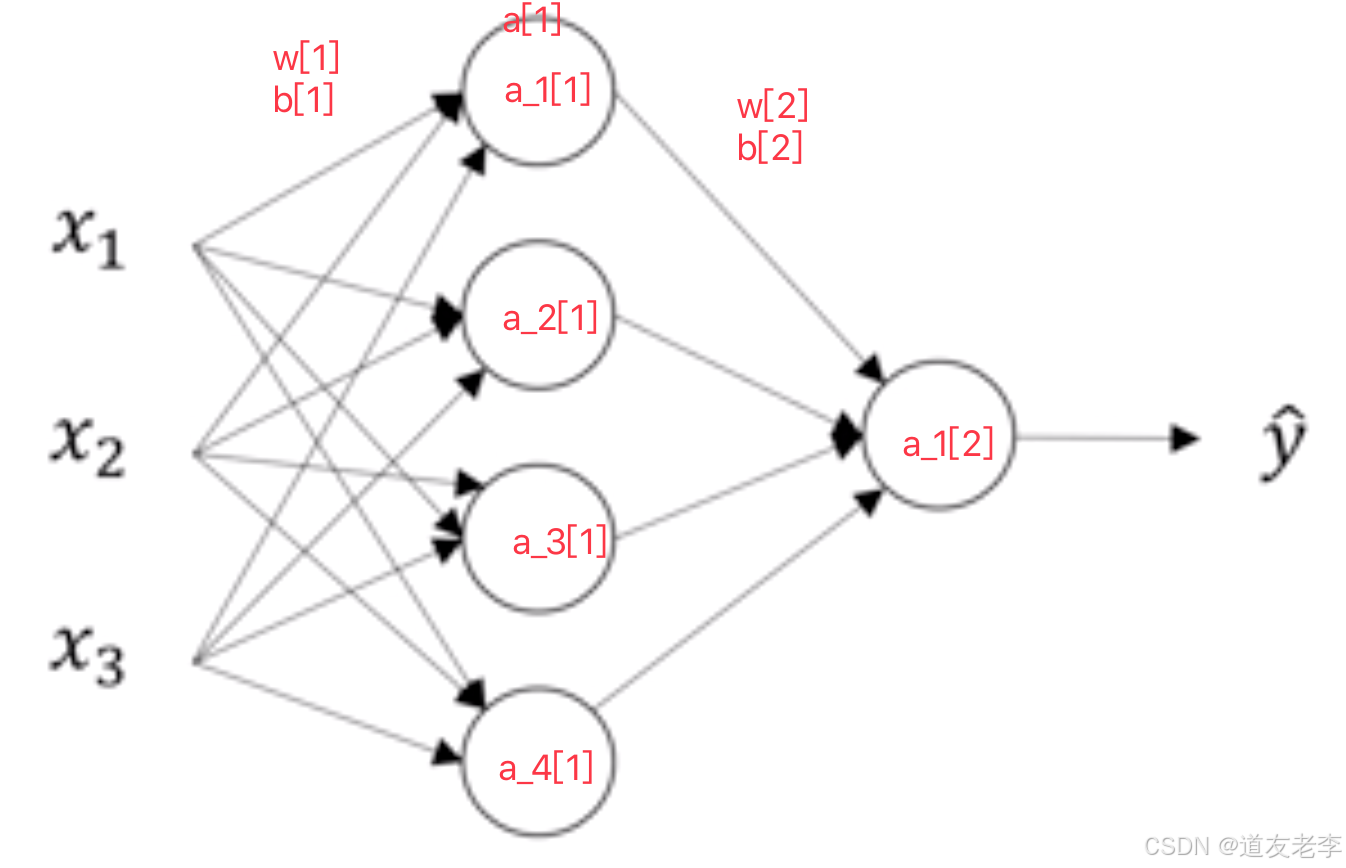
计算图如下
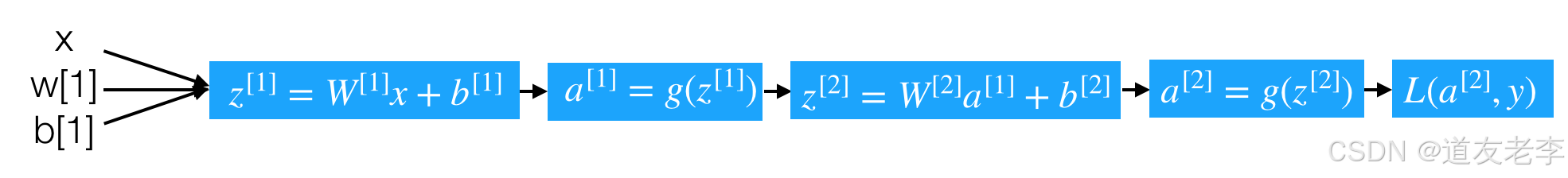
- 每个神经元的计算分解步骤如下
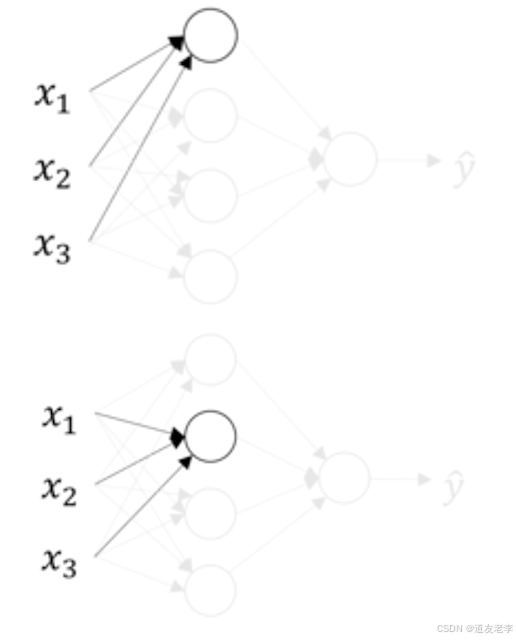
- 第一层中的第一个神经元
z 1 [ 1 ] = ( W 1 [ 1 ] ) T x + b 1 [ 1 ] z _1^{[1]} = (W _1^{[1]})^Tx+b _1^{[1]} z1[1]=(W1[1])Tx+b1[1]
a 1 [ 1 ] = σ ( z 1 [ 1 ] ) a _1^{[1]} = \sigma(z _1^{[1]}) a1[1]=σ(z1[1])
- 第一层中的第一个神经元
z 2 [ 1 ] = ( W 2 [ 1 ] ) T x + b 2 [ 1 ] z _2^{[1]} = (W _2^{[1]})^Tx+b _2^{[1]} z2[1]=(W2[1])Tx+b2[1]
a 2 [ 1 ] = σ ( z 2 [ 1 ] ) a _2^{[1]} = \sigma(z _2^{[1]}) a2[1]=σ(z2[1])
得出第一层的计算:
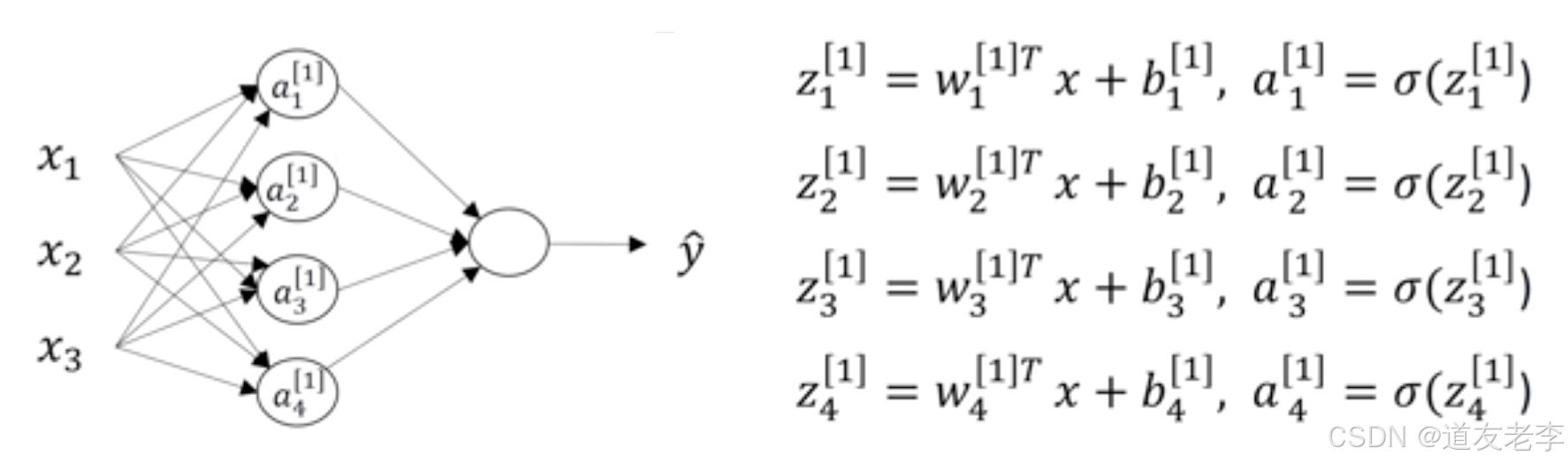
1.3.2 单个样本的向量化表示
那么现在把上面的第一层的计算过程过程用更简单的形式表现出来就是这样的计算
( ⋯ ( W 1 [ 1 ] ) T ⋯ ⋯ ( W 2 [ 1 ] ) T ⋯ ⋯ ( W 3 [ 1 ] ) T ⋯ ⋯ ( W 4 [ 1 ] ) T ⋯ ) ∗ ( x 1 x 2 x 3 ) + ( b 1 [ 1 ] b 2 [ 1 ] b 3 [ 1 ] b 4 [ 1 ] ) \left(\begin{array}{cccc}\cdots & (W _1^{[1]})^T & \cdots \\ \cdots & (W _2^{[1]})^T & \cdots \\ \cdots & (W _3^{[1]})^T & \cdots \\ \cdots & (W _4^{[1]})^T & \cdots \end{array}\right) * \left( \begin{array}{c}x_{1} \\ x_{2} \\ x_{3}\end{array}\right) + \left( \begin{array}{c}b_{1}^{[1]} \\ b_{2}^{[1]} \\ b_{3}^{[1]} \\ b_{4}^{[1]} \end{array}\right) ⋯⋯⋯⋯(W1[1])T(W2[1])T(W3[1])T(W4[1])T⋯⋯⋯⋯ ∗ x1x2x3 + b1[1]b2[1]b3[1]b4[1]
那么对于刚才我们所举的例子,将所有层通过向量把整个前向过程表示出来,并且确定每一个组成部分的形状
前向过程计算:
z [ 1 ] = W [ 1 ] x + b [ 1 ] 形状: ( 4 , 1 ) = ( 4 , 3 ) ∗ ( 3 , 1 ) + ( 4 , 1 ) z^{[1]} = W^{[1]}x+b^{[1]} 形状:(4,1) = (4,3) * (3,1) + (4,1) z[1]=W[1]x+b[1]形状:(4,1)=(4,3)∗(3,1)+(4,1)
a [ 1 ] = σ ( z [ 1 ] ) a^{[1]}=\sigma(z^{[1]}) a[1]=σ(z[1])形状:(4,1)
z [ 2 ] = W [ 2 ] a [ 1 ] + b [ 2 ] z^{[2]} = W^{[2]}a^{[1]}+b^{[2]} z[2]=W[2]a[1]+b[2] 形状:(1,1) = (1,4) * (4,1)+(1,1)
a [ 2 ] = σ ( z [ 2 ] ) a^{[2]}=\sigma(z^{[2]}) a[2]=σ(z[2])形状:(1,1)
那么如果有多个样本,需要这样去做
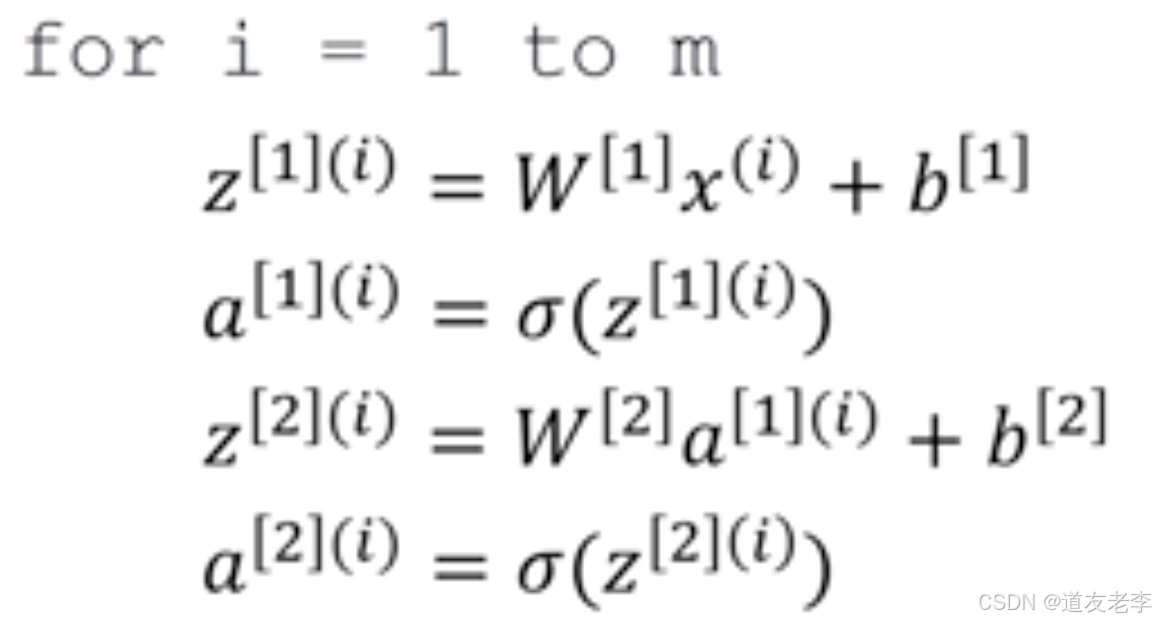
- 多个样本的向量化表示
假设一样含有M个样本,那么上述过程变成
Z [ 1 ] = W [ 1 ] X + b [ 1 ] Z^{[1]} = W^{[1]}X+b^{[1]} Z[1]=W[1]X+b[1] 形状:(4,m) = (4,3) * (3,m) + (4,1)
A [ 1 ] = σ ( Z [ 1 ] ) {A}^{[1]}=\sigma(Z^{[1]}) A[1]=σ(Z[1])形状:(4,m)
Z [ 2 ] = W [ 2 ] A [ 1 ] + b [ 2 ] Z^{[2]} = W^{[2]}A^{[1]}+b^{[2]} Z[2]=W[2]A[1]+b[2]形状:(1,m) = (1,4) * (4,m)+(1,1)
A [ 2 ] = σ ( Z [ 2 ] ) A^{[2]}=\sigma(Z^{[2]}) A[2]=σ(Z[2])形状:(1,m)
1.3.4 激活函数的选择
涉及到网络的优化时候,会有不同的激活函数选择有一个问题是神经网络的隐藏层和输出单元用什么激活函数。之前我们都是选用 sigmoid 函数,但有时其他函数的效果会好得多,大多数通过实践得来,没有很好的解释性。
可供选用的激活函数有:
- tanh 函数(the hyperbolic tangent function,双曲正切函数):
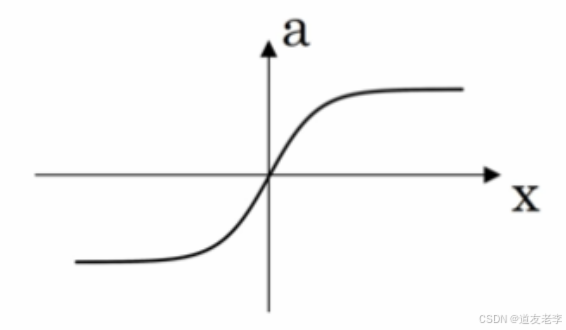
效果比 sigmoid 函数好,因为函数输出介于 -1 和 1 之间。
注 :tanh 函数存在和 sigmoid 函数一样的缺点:当 z 趋紧无穷大(或无穷小),导数的梯度(即函数的斜率)就趋紧于 0,这使得梯度算法的速度会减慢。
- ReLU 函数(the rectified linear unit,修正线性单元)
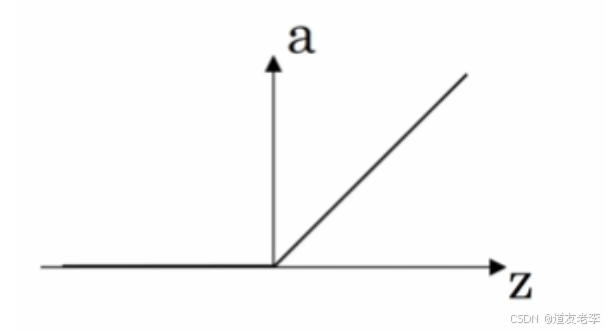
当 z > 0 时,梯度始终为 1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于 sigmoid 和 tanh。然而当 z < 0 时,梯度一直为 0,但是实际的运用中,该缺陷的影响不是很大。
-
Leaky ReLU(带泄漏的 ReLU):
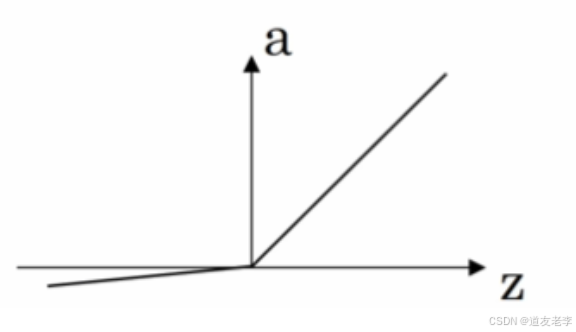
Leaky ReLU 保证在 z < 0 的时候,梯度仍然不为 0。理论上来说,Leaky ReLU 有 ReLU 的所有优点,但在实际操作中没有证明总是好于 ReLU,因此不常用。
1.3.4.1 为什么需要非线性的激活函数
使用线性激活函数和不使用激活函数、直接使用 Logistic 回归没有区别,那么无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,就成了最原始的感知器了。
a [ 1 ] = z [ 1 ] = W [ 1 ] x + b [ 1 ] a^{[1]} = z^{[1]} = W^{[1]}x+b^{[1]} a[1]=z[1]=W[1]x+b[1]
a [ 2 ] = z [ 2 ] = W [ 2 ] a [ 1 ] + b [ 2 ] {a}^{[2]}=z^{[2]} = W^{[2]}a^{[1]}+b^{[2]} a[2]=z[2]=W[2]a[1]+b[2]
那么这样的话相当于
a [ 2 ] = z [ 2 ] = W [ 2 ] ( W [ 1 ] x + b [ 1 ] ) + b [ 2 ] = ( W [ 2 ] W [ 1 ] ) x + ( W [ 2 ] b [ 1 ] + b [ 2 ] ) = w x + b {a}^{[2]}=z^{[2]} = W^{[2]}(W^{[1]}x+b^{[1]})+b^{[2]}=(W^{[2]}W^{[1]})x+(W^{[2]}b^{[1]}+b^{[2]})=wx+b a[2]=z[2]=W[2](W[1]x+b[1])+b[2]=(W[2]W[1])x+(W[2]b[1]+b[2])=wx+b
1.3.5 修改激活函数的前向传播和反向传播
将上述网络的隐层激活函数修改为tanh,最后一层同样还是二分类,所以激活函数选择依然是sigmoid函数
- 前向传播
Z [ 1 ] = W [ 1 ] X + b [ 1 ] Z^{[1]} = W^{[1]}X+b^{[1]} Z[1]=W[1]X+b[1]
A [ 1 ] = t a n h ( Z [ 1 ] ) {A}^{[1]}=tanh(Z^{[1]}) A[1]=tanh(Z[1])
Z [ 2 ] = W [ 2 ] A [ 1 ] + b [ 2 ] Z^{[2]} = W^{[2]}A^{[1]}+b^{[2]} Z[2]=W[2]A[1]+b[2]
A [ 2 ] = σ ( Z [ 2 ] ) A^{[2]}=\sigma(Z^{[2]}) A[2]=σ(Z[2])
- 反向梯度下降
那么通过这个计算图来理解这个过程,单个样本的导数推导过程:
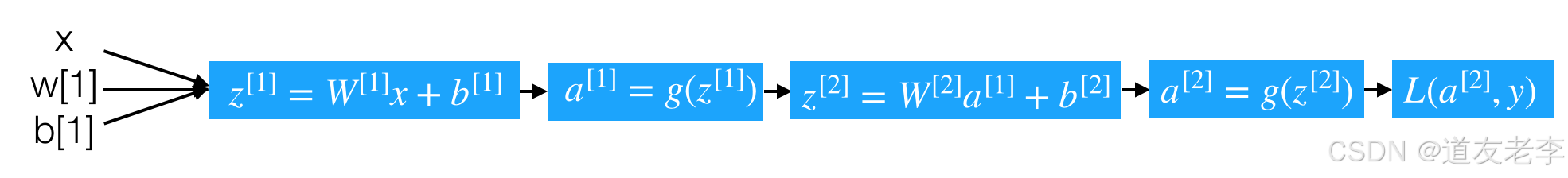
由于网络已经存在两层,所以我们需要从后往前得到导数结果,并且多个样本的情况下改写成
最后一个输出层的参数的导数:
d Z [ 2 ] = A [ 2 ] − Y dZ^{[2]} = A^{[2]} - Y dZ[2]=A[2]−Y
d W [ 2 ] = 1 m d Z [ 2 ] A [ 1 ] T dW^{[2]}=\frac{1}{m}dZ^{[2]}{A^{[1]}}^{T} dW[2]=m1dZ[2]A[1]T
d b [ 2 ] = 1 m n p . s u m ( d Z [ 2 ] , a x i s = 1 ) db^{[2]}=\frac{1}{m}np.sum(dZ^{[2]}, axis=1) db[2]=m1np.sum(dZ[2],axis=1)
隐藏层的导数计算:
d Z [ 1 ] = W [ 2 ] T d Z [ 2 ] ∗ ( 1 − g ( Z [ 1 ] ) 2 = W [ 2 ] T d Z [ 2 ] ∗ ( 1 − A [ 1 ] ) 2 dZ^{[1]} = {W^{[2]}}^{T}dZ^{[2]}*{(1-g(Z^{[1]})}^{2}={W^{[2]}}^{T}dZ^{[2]}*{(1-A^{[1]})}^{2} dZ[1]=W[2]TdZ[2]∗(1−g(Z[1])2=W[2]TdZ[2]∗(1−A[1])2
d W [ 1 ] = 1 m d Z [ 1 ] X T dW^{[1]}=\frac{1}{m}dZ^{[1]}X^{T} dW[1]=m1dZ[1]XT
d b [ 1 ] = 1 m n p . s u m ( d Z [ 1 ] , a x i s = 1 ) db^{[1]} = \frac{1}{m}np.sum(dZ^{[1]}, axis=1) db[1]=m1np.sum(dZ[1],axis=1)
评论记录:
回复评论: