

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈智能大数据分析 ⌋ ⌋ ⌋ 智能大数据分析是指利用先进的技术和算法对大规模数据进行深入分析和挖掘,以提取有价值的信息和洞察。它结合了大数据技术、人工智能(AI)、机器学习(ML)和数据挖掘等多种方法,旨在通过自动化的方式分析复杂数据集,发现潜在的价值和关联性,实现数据的自动化处理和分析,从而支持决策和优化业务流程。与传统的人工分析相比,智能大数据分析具有自动化、深度挖掘、实时性和可视化等特点。智能大数据分析广泛应用于各个领域,包括金融服务、医疗健康、零售、市场营销等,帮助企业做出更为精准的决策,提升竞争力。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/Intelligent_bigdata_analysis。
一、智能推荐简介
(一)什么是推荐系统
现代人在生活中经常遭遇选择困难的问题,在这个信息爆发的时代,飞速增长的信息让人眼花缭乱,不知道如何去选择适合自己的商品。人们往往会询问身边的朋友,请这些“专家”推荐几个他们认为较好的选择。虽然这些建议能帮助我们有效过滤掉一些多余的信息,但并没有考虑到个人个性化的需求,往往是基于更为偏向大众化的需求。
由于不能总是找到一位“专家”提建议,因此人们需要一个更为自动化的工具,这个工具能够分析用户以往的历史数据,以这些数据作为依托,为用户提供更为个性化定制的建议,这就是智能推荐系统。推荐系统作为连接消费者与生产者的桥梁起到了非常关键的作用,消费者通过推荐系统从大量同类商品中能更为轻松的找到自己感兴趣的商品,而生产者也能通过推荐系统从大量竞争者中脱颖而出,得到自己的目标用户的青睐。
(二)智能推荐的应用
一项技术能否广泛应用往往与需求有很强的联系。在互联网的早期,门户咨询网站已经能满足用户绝大部分的需求,这些门户网站的主要内容是编辑整理出的堆叠在网页之上的一堆链接,如国内的hao123网站。
之后的十几年,互联网进入了爆发期,面对日益增长的资讯量,门户网站已经无法满足用户的需求,此时出现了RSS订阅。RSS订阅为用户提供了个性化的体验,由于每个人订阅的信息源不一样,所以看到的咨询列表也不一样。
虽然RSS订阅让用户首次体验到了个性化的优异之处,但是由于订阅工具的使用存在难度且订阅源难以寻找,导致普及率一直不高。虽然RSS订阅已淡出了舞台,但是它为智能推荐起到了铺垫作用,用户已经尝到了个性化的甜头,由机器进行个性化推荐自然而然地得到了广泛应用。目前,智能推荐的应用领域已经涵盖电子商务、视频网站、音乐、社交网络、基于位置的服务和广告等多个领域。
1. 电子商务
电子商务已经成为智能推荐的最为普及的领域之一,在国内外的各大电子商务网站上智能推荐系统都得到了不错的成效。
国外著名的电子商务网站亚马逊被RWW(读写网)誉为“推荐系统之王”,该网站最主要的推荐系统应用为个性化商品推荐列表和相关商品推荐列表。亚马逊会根据用户的历史行为为用户做推荐,如果用户曾经对一本编程语言的书给出了高评价,那么亚马逊很可能会在推荐列表中推荐类似的学习书籍。推荐系统的应用成功地为亚马逊带来了额外的收入增长,据亚马逊的前首席科学家韦思岸(Andreas Weigend)在斯坦福的一次推荐系统的讲课过程中透露,亚马逊有20%~30%的销售业绩来自于推荐系统。
国内的电商平台也普遍运用了推荐系统,如淘宝网和京东的“猜你喜欢”和“您可能还需要”栏目也是为人们所熟知的推荐系统应用。
2. 视频网站
在视频网站中个性化推荐系统也得到了很好的应用。用户通过推荐系统的帮助在浩如星海的视频库成功找到自己感兴趣的视频作品,视频作者也成功收获了更多的关注。
国内的优酷、爱奇艺、BiliBili等视频网站都有应用推荐系统进行推荐引流,而在应用推荐系统最为出名的还有国外网站Netflix和YouTube。Netflix使用与亚马逊策略类似的基于物品的推荐系统,该系统会为用户推荐与他们喜欢过的电影类似的电影,帮助了Netflix中60%的用户成功找到自己感兴趣的电影和视频。而YouTube所做的一个个性化推荐和热门视频列表的点击率比较的实验的结果表明,个性化推荐的点击率为热门视频列表的点击率的两倍。
3. 音乐
个性化的网络电台也非常适合使用推荐系统,因为每年新的歌曲都在以极快的速度增长,用户想要寻找自己钟情的歌曲无异于大海捞针。其次,大部分用户在日常生活中都是将音乐作为背景音乐,只有很小一部分群体会听某首特定的歌,对于普通用户,只要推荐的歌曲符合用户当时的心境即可。
国内的网易云音乐的私人FM就是一个很典型的应用了推荐系统的个性化网络电台,私人FM不提供点歌功能,只提供了3个选项,即喜欢、垃圾桶和跳过,用户根据对系统推荐的歌曲的不同感受选择对应的选项,在经过一段时间后,推荐的歌曲列表将更为符合用户的口味。
4. 社交网络
近几年社交网络应用在互联网上迅速崛起,以Facebook和Twitter为代表的社交网络产品迅速风靡全球。推荐系统在社交网络上的应用主要分为两类,依据用户点赞和转发过的内容,根据标签推荐用户可能感兴趣的内容,或依据用户关注的人和内容推荐兴趣类似的好友。
5. 基于位置的服务
随着移动设备的发展,用户的位置信息已经能够很容易获取到,位置信息包含了很强的上下文关系信息。如用户在用餐时间打开服务,而用户正好身处商业区,那么此时已打开的服务很可能会为用户推荐附近的餐饮信息。
6. 广告
目前广告收入仍然是很多互联网公司收入的根基,随机投放的广告效率低很容易造成资源浪费,并且会有降低用户体验的负面影响。
而精准化的定向广告投放很适合使用个性化推荐系统实现,与一般的个性化推荐系统不同,个性化广告投放以广告为中心,寻找可能对广告感兴趣的用户。而一般的个性化推荐是以用户为中心,推荐用户感兴趣的内容。
二、智能推荐性能度量
评价一个推荐系统的方法有很多,总体可分为三个方面:
- 离线实验
- 用户调查
- 在线实验
由于用户调查和在线实验的要求较高,目前大多数的推荐系统研究采用的是先通过离线实验验证当前的推荐算法在离线指标上是否优于现有算法,然后通过用户调查确定当前算法的满意度不低于现有算法。这两项都通过后,最后才进行在线测试查看测试者所关注的当前算法的指标是否优于现有算法。
(一)离线实验评价指标
离线实验主要基于数据集,不需要实际的系统做支撑,因此测试成本更为低廉,流程也更为简便。离线实验的评价步骤如下。
- 通过业务系统获取用户行为数据,生成标准数据集。
- 将数据集进行划分,划分为训练集和测试集。
- 在训练集上进行推荐模型的训练,在测试集上进行预测。
- 通过离线评价指标评价模型在测试集上的的预测结果。
离线实验的评价指标可分为准确性指标和非准确性指标两种。
1. 准确性指标
准确性指标是评价推荐系统预测的准确性的指标,是推荐系统中最重要的指标。推荐的结果类型不同,适用的准确性指标也不一样。
(1)推荐列表
通常网站给用户进行推荐时,针对每个用户提供的是一个个性化的推荐列表,也叫作TopN推荐。TopN推荐最常用的准确性指标是准确率、召回率和 F 1 F_1 F1值。准确率表示推荐列表中用户喜欢的物品所占的比例。单个用户 u u u的推荐准确率定义如下。 P ( L u ) = L u ∩ B u L u P(L_u)=\frac{L_u \cap B_u}{L_u} P(Lu)=LuLu∩Bu 其中, L u L_u Lu表示用户 u u u的推荐列表, B u B_u Bu表示测试集中用户 u u u喜欢的物品。
整个推荐系统的准确率定义如下,其中 U U U表示用户集。 P L = 1 n ∑ u ∈ U P ( L u ) P_L=\frac{1}{n}\sum_{u\in U}P(L_u) PL=n1u∈U∑P(Lu)
召回率表示测试集中用户喜欢的物品出现在推荐列表中的比例。单个用户 u u u的推荐召回率定义如下。 R ( L u ) = L u ∩ B u B u R(L_u)=\frac{L_u\cap B_u}{B_u} R(Lu)=BuLu∩Bu
整个推荐系统的召唤率定义如下。 R L = 1 n ∑ u ∈ U R ( L u ) R_L=\frac{1}{n}\sum_{u\in U}R(L_u) RL=n1u∈U∑R(Lu)
值(F1 score)是综合了准确率( P P P)和召回率( R R R)的评价方法, F 1 F_1 F1值取值越高表明推荐算法越有效, 值定义如下。 F 1 = 2 P R P + R F_1=\frac{2PR}{P+R} F1=P+R2PR
(2)评分预测
评分预测是指预测一个用户对推荐的物品的评分。评分预测的预测准确度通过均方根误差(RMSE)和平均绝对误差(MAE)进行评价。
对于测试集 T T T中的用户 u u u和 i i i物品 ,定义用户 u u u对物品 i i i的实际评分为 r u i r_{ui} rui,推荐算法的预测评分为 r ^ u i \hat r_{ui} r^ui,则RMSE的定义如下。 R M S E = ∑ u , i ∈ T ( r u i − r ^ u i ) 2 ∣ T ∣ \mathrm{RMSE}=\frac{\sqrt{\sum\limits_{u,i\in T}(r_{ui}-\hat r_{ui})^2}}{|T|} RMSE=∣T∣u,i∈T∑(rui−r^ui)2
MAE使用绝对值计算,定义如下。 M A E = ∑ u , i ∈ T ∣ r u i − r ^ u i ∣ ∣ T ∣ \mathrm{MAE}=\frac{\sum\limits_{u,i\in T}|r_{ui}-\hat r_{ui}|}{|T|} MAE=∣T∣u,i∈T∑∣rui−r^ui∣
2. 非准确性指标
除了推荐准确性指标外,还有许多其他指标能评价一个推荐算法的性能,如多样性、新颖性、惊喜度和覆盖率等。
(1)多样性
用户的兴趣是广泛而多样的,所以推荐列表需要尽可能多的覆盖到用户的兴趣领域。多样性越高的推荐系统,用户访问时找到喜好的物品的概率就更高。推荐列表中物品两两之间的不相似性即为推荐列表的多样性,将物品 i i i和 j j j之间的相似度定义为 ( i , j ) ∈ [ 0 , 1 ] (i,j)\in [0,1] (i,j)∈[0,1],则用户 u u u的推荐列表 R ( u ) R(u) R(u)的多样性定义如下。 D i v e r s i t y = 1 − ∑ i , j ∈ R ( u ) , i ≠ j s ( i , j ) 1 2 ∣ R ( u ) ∣ [ ∣ R ( u ) ∣ − 1 ] \mathrm{Diversity}=1-\frac{\sum\limits_{i,j\in R(u),i\ne j}s(i,j)}{\frac{1}{2}\lvert R(u)\rvert[\lvert R(u)\rvert-1]} Diversity=1−21∣R(u)∣[∣R(u)∣−1]i,j∈R(u),i=j∑s(i,j)
推荐系统的整体多样性可以定义为全部用户的推荐列表多样性的平均值,如下。 D i v e r s i t y = 1 ∣ U ∣ ∑ u ∈ U D i v e r s i t y ( R ( u ) ) \mathrm{Diversity}=\frac{1}{|U|}\sum_{u\in U}\mathrm{Diversity}(R(u)) Diversity=∣U∣1u∈U∑Diversity(R(u))
(2)新颖性
当推荐系统推荐给用户的物品是用户未曾听说过的物品,那么这次推荐对于用户来说就是一次新颖的推荐。评价新颖度的一个简单的方法是利用推荐结果的平均流行度。推荐物品的流行度越低,物品越不热门,越可能让用户觉得新颖。若推荐结果中物品的平均流行度较低,那么推荐结果可能拥有较高的新颖性。
定义物品 i i i的流行度为 p ( i ) p(i) p(i),则用户 u u u的推荐列表 L u L_u Lu的新颖性定义如下。 N o v e l t y ( L u ) = ∑ i ∈ L u p ( i ) ∣ L u ∣ \mathrm{Novelty}(L_u)=\frac{\sum\limits_{i\in L_u}p(i)}{|L_u|} Novelty(Lu)=∣Lu∣i∈Lu∑p(i)
推荐系统的整体新颖性可以定义为全部用户的推荐列表新颖性的平均值,计算公式如下。 N o v e l t y = 1 n ∑ n ∈ U N o v e l t y ( L u ) \mathrm{Novelty}=\frac{1}{n}\sum_{n\in U}\mathrm{Novelty}(L_u) Novelty=n1n∈U∑Novelty(Lu)
(3)惊喜度
惊喜度与新颖性的区别在于,新颖性指的是推荐给用户的物品是用户没有听说过的物品,而惊喜度是指推荐给用户的物品与用户历史记录中感兴趣的物品不相似,但是用户却又觉得满意。目前尚未有一个公认的惊喜度指标的定义方式,此处只给出一种定性的度量方式。
(4)覆盖率
覆盖率用于描述一个推荐系统对于物品长尾的挖掘能力。覆盖率最常见的定义是推荐系统推荐出的物品列表中的物品数目占总物品集合中物品数目的比例。定义用户 u u u的推荐列表为 L u L_u Lu,则推荐系统的覆盖率定义如下。 C o v e r a g e = ∣ ⋃ u ∈ U L u ∣ n \mathrm{Coverage}=\frac{\left|\bigcup\limits_{u\in U}L_u\right|}{n} Coverage=n u∈U⋃Lu
(二)用户调查评价指标
离线实验的指标和实际的商业指标存在一定的差距,一个拥有较高预测准确率的推荐系统并不一定拥有更高的用户满意度。要准确评价一个推荐算法,除了离线实验,还需要一个相对真实的环境进行测试。在无法确定算法是否会降低用户满意度的情况下,直接进行上线测试会有较高的风险,因此通常会在上线测试前进行一次用户调查测试。
用户作为推荐系统的重要参与者,用户满意度是评测推荐系统的最重要指标。用户调查获得用户满意度主要是通过调查问卷的形式。设计问卷时需要从不同的侧面询问用户对推荐结果的不同感受,而不是简单直接地询问用户对推荐结果是否满意,这样用户才能针对问题给出自己准确的回答。
(三)在线实验评价指标
在推荐系统完成离线实验和用户调查后,就可以进行上线做AB测试,与旧的现有算法进行比较。AB测试是一种常见的在线评测算法的实验方法,通过将用户随机分成几组,对不同组用户采用不同算法进行对照,通过统计不同组用户的各种评测指标比较不同算法的效果。在线实验时的评价指标常见的有实时性、健壮性、用户满意度和商业指标等。
1. 实时性
由网站中的物品往往具有很强的时效性,如新闻、微博等,因此需要在时效性尚未消失的时候就推荐给用户。
推荐系统的实时性体现为两个方面,一个为能够实时地更新推荐列表满足用户的新的行为变化,通过推荐列表的变化速率进行评测;另一个为推荐系统能够将新加入系统的物品推荐给用户,通过用户推荐列表中新加物品所占比例进行评测。
2. 健壮性
在线上运行的算法系统不可避免地会遭受被人攻击的问题,对于推荐系统而言,最常见的攻击就是作弊问题,健壮性指标衡量了一个推荐系统抗作弊的能力。
推荐系统的健壮性的评测主要通过模拟攻击进行,在给定一个数据集和算法的情况下,利用算法给数据集中的用户生成推荐列表。之后用常用攻击方法向数据集中注入噪声后再使用相同的算法生成推荐列表。对攻击前后的推荐列表的相似度进行评价,从而评价推荐算法的健壮性。
3. 用户满意度
在线系统中的用户满意度主要通过一些用户行为的统计结果得到,最常见的情况是通过点击率、用户停留时间和转化率等指标度量用户的满意度。
4. 商业指标
在实际应用中,对于线上运行的推荐系统能否帮助达成商业目标是十分重要的。最简单直接的表现是上线推荐系统后能否加速完成商业指标,如销售额、广告点击数等,不同的网站拥有不同的指标,这些指标本质为上线系统能否为网站带来更多的盈利。
三、基于关联规则的智能推荐
关联规则可以挖掘出物品间的关联关系,物品间的关联性越强推荐给用户时越可能受用户喜欢,提取关联规则的最大困难在于当存在很多商品时,可能的商品的组合(规则的前项与后项)的数目会达到一种令人望而却步的程度。
因此,各种关联规则分析的算法会从不同方面入手减小可能的搜索空间的大小以及减小扫描数据的次数。目前常见的关联规则算法有:
- Apriori
- FP-Growth
(一)关联规则和频繁项集
1. 关联规则的一般形式
项集 A A A、 B B B同时发生的概率称为关联规则的支持度(也称相对支持度) S u p p o r t ( A ⇒ B ) = P ( A ∩ B ) \mathrm{Support}(A\Rightarrow B)=P(A\cap B) Support(A⇒B)=P(A∩B)
项集 A A A发生,则项集 B B B发生的概率为关联规则的置信度 C o n f i d e n c e ( A ⇒ B ) = P ( B ∣ A ) \mathrm{Confidence}(A\Rightarrow B)=P(B|A) Confidence(A⇒B)=P(B∣A)
2. 最小支持度和最小置信度
最小支持度是用户或专家定义的衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性。
最小置信度是用户或专家定义的衡量置信度的一个阈值,表示关联规则的最低可靠性。
同时满足最小支持度阈值和最小置信度阈值的规则被称作强规则。
3. 项集
项集是项的集合。包含
k
k
k个项的项集称为
k
k
k项集,如集合
{
牛奶
,
麦片
,
糖
}
\{牛奶,麦片,糖\}
{牛奶,麦片,糖}是一个3项集。
项集的出现频数是所有包含项集的事务计数,又被称作绝对支持度或支持度计数。
如果项集
I
I
I的相对支持度满足预定义的最小支持度阈值,则
I
I
I是频繁项集。频繁
k
k
k项集通常记作
L
k
L_k
Lk。
4. 支持度计数
项集 A A A的支持度计数是事务数据集中包含项集 A A A的事务个数,简称为项集的频率或计数。已知项集的支持度计数,则规则 A ⇒ B A\Rightarrow B A⇒B的支持度和置信度很容易从所有事务计数、项集 A A A和项集 A ∪ B A\cup B A∪B的支持度计数推出式如下,其中 N N N表示总事务个数, σ \sigma σ表示计数。 S u p p o r t ( A ⇒ B ) = A , B 同时发生的事务个数 所有事务个数 = σ ( A ∪ B ) N \mathrm{Support}(A\Rightarrow B)=\frac{A,B同时发生的事务个数}{所有事务个数}=\frac{\sigma(A\cup B)}{N} Support(A⇒B)=所有事务个数A,B同时发生的事务个数=Nσ(A∪B) C o n f i d e n c e ( A ⇒ B ) = P ( B ∣ A ) = σ ( A ∪ B ) σ ( A ) \mathrm{Confidence}(A\Rightarrow B)=P(B|A)=\frac{\sigma(A\cup B)}{\sigma(A)} Confidence(A⇒B)=P(B∣A)=σ(A)σ(A∪B)
也就是说,一旦得到所有事务个数, A A A、 B B B和 A ∪ B A\cup B A∪B的支持度计数,即可导出对应的关联规则 A ⇒ B A\Rightarrow B A⇒B和 B ⇒ A B\Rightarrow A B⇒A,并可以检查该规则是否是强规则。
(二)Apriori算法
Apriori算法的主要思想是找出存在于事务数据集中的最大的频繁项集,再利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
1. Apriori算法实现的两个过程
频繁项集的所有非空子集也必须是频繁项集。根据该性质可以得出:向不是频繁项集 I I I的项集 I I I中添加事务 A A A,新的项集 I ∪ A I\cup A I∪A一定也不是频繁项集。
找出所有的频繁项集(支持度必须大于等于给定的最小支持度阈值),在这个过程中连接步和剪枝步互相融合,最终得到最大频繁项集 L k L_k Lk。
(1)连接步
连接步的目的是找到 K K K项集。对给定的最小支持度阈值,对1项候选集 C 1 C_1 C1,剔除小于该阈值的项集得到1项频繁项集 L 1 L_1 L1;下一步由 L 1 L_1 L1自身连接产生2项候选集 C 2 C_2 C2,保留 C 2 C_2 C2中满足约束条件的项集得到2项频繁项集,记为 L 2 L_2 L2;再下一步由 L 2 L_2 L2与 L 1 L_1 L1连接产生3项候选集 C 3 C_3 C3,保留 C 2 C_2 C2中满足约束条件的项集得到3项频繁项集,记为 L 3 L_3 L3。这样循环下去,得到最大频繁项集 L k L_k Lk。
(2)剪枝步
剪枝步紧接着连接步,在产生候选项 L k L_k Lk的过程中起到减小搜索空间的目的。由于 C k C_k Ck是 L k − 1 L_{k-1} Lk−1与 L 1 L_1 L1连接产生的,根据Apriori的性质频繁项集的所有非空子集也必须是频繁项集,所以不满足该性质的项集将不会存在于 C k C_k Ck中,该过程就是剪枝。
由频繁项集产生强关联规则:由过程(1)可知,未超过预定的最小支持度阈值的项集已被剔除,如果剩下这些项集又满足了预定的最小置信度阈值,那么就挖掘出了强关联规则。
2. 使用Apriori算法实现餐饮菜品关联分析
结合餐饮行业的实例讲解Apriori关联规则算法挖掘的实现过程。数据库中部分点餐数据如表所示。
| 序列 | 时间 | 订单号 | 菜品id | 菜品名称 |
|---|---|---|---|---|
| 1 | 2014/8/21 | 101 | 18491 | 健康麦香包 |
| 2 | 2014/8/21 | 101 | 8693 | 香煎葱油饼 |
| 3 | 2014/8/21 | 101 | 8705 | 翡翠蒸香茜饺 |
| 4 | 2014/8/21 | 102 | 8842 | 菜心粒咸骨粥 |
| 5 | 2014/8/21 | 102 | 7794 | 养颜红枣糕 |
| 6 | 2014/8/21 | 103 | 8842 | 金丝燕麦包 |
| 7 | 2014/8/21 | 103 | 8693 | 三丝炒河粉 |
| …… | …… | …… | …… | …… |
首先将上表中的事务数据(一种特殊类型的记录数据)整理成关联规则模型所需的数据结构,从中抽取10个点餐订单作为事务数据集,设支持度为0.2(支持度计数为2),为方便起见将菜品 { 18491 , 8842 , 8693 , 7794 , 8705 } \{18491,8842,8693,7794,8705\} {18491,8842,8693,7794,8705}分别简记为 { a , b , c , d , e } \{a,b,c,d,e\} {a,b,c,d,e},如表所示。
| 订单号 | 原菜品id | 转换后菜品id |
|---|---|---|
| 1 | 18491, 8693, 8705 | a , c , e a, c, e a,c,e |
| 2 | 8842, 7794 | b , d b, d b,d |
| 3 | 8842, 8693 | b , c b, c b,c |
| 4 | 18491, 8842, 8693, 7794 | a , b , c , d a, b, c, d a,b,c,d |
| 5 | 18491, 8842 | a , b a, b a,b |
| 6 | 8842, 8693 | b , c b, c b,c |
| 7 | 18491, 8842 | a , b a, b a,b |
| 8 | 18491, 8842, 8693, 8705 | a , b , c , e a, b, c, e a,b,c,e |
| 9 | 18491, 8842, 8693 | a , b , c a, b, c a,b,c |
| 10 | 18491, 8693 | a , c , e a, c, e a,c,e |
算法过程如图所示。
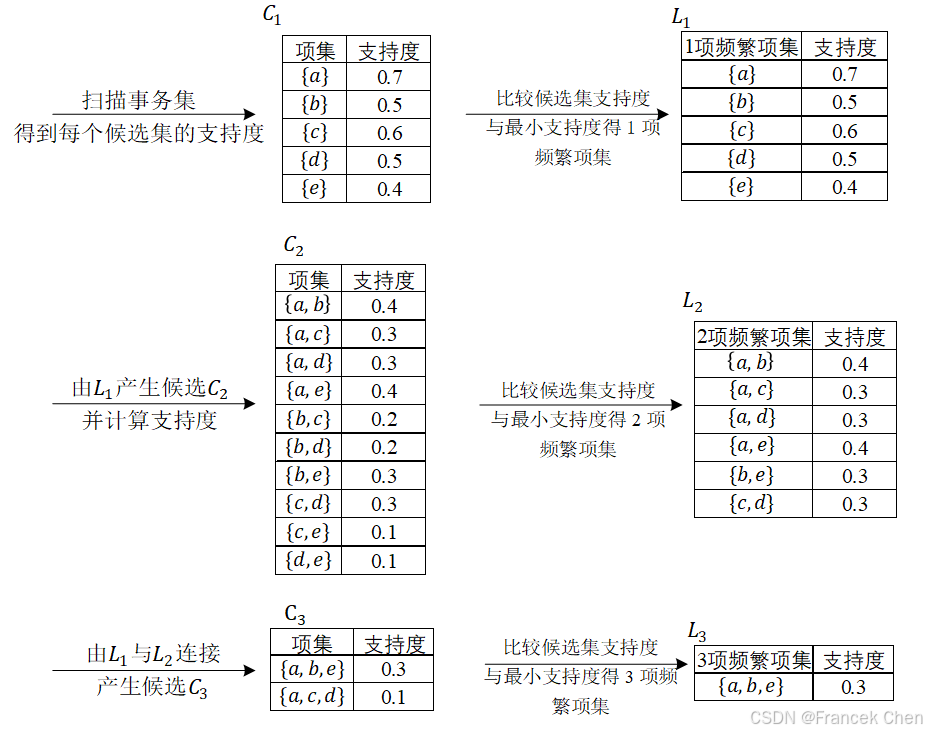
(1)过程一:找最大k项频繁项集
算法简单扫描所有的事务,事务中的每一项都是候选1项集的集 C 1 C_1 C1的成员,计算每一项的支持度。如 P ( { a } ) = 项集 { a } 的支持度计数 所有事务个数 = 7 10 = 0.7 P(\{a\})=\frac{项集\{a\}的支持度计数}{所有事务个数}=\frac{7}{10}=0.7 P({a})=所有事务个数项集{a}的支持度计数=107=0.7
对 C 1 C_1 C1中各项集的支持度与预先设定的最小支持度阈值作比较,保留大于或等于该阈值的项,得1项频繁项集 L 1 L_1 L1。
扫描所有事务, L 1 L_1 L1与 L 1 L_1 L1连接得候选2项集 C 2 C_2 C2,并计算每一项的支持度。如 P ( { a , b } ) = 项集 { a , b } 的支持度计数 所有事务个数 = 5 10 = 0.5 P(\{a,b\})=\frac{项集\{a,b\}的支持度计数}{所有事务个数}=\frac{5}{10}=0.5 P({a,b})=所有事务个数项集{a,b}的支持度计数=105=0.5
接着是剪枝步,由于 C 2 C_2 C2的每个子集(即 L 1 L_1 L1)都是频繁项集,所以没有项集从 C 2 C_2 C2中剔除。对 C 2 C_2 C2中各项集的支持度与预先设定的最小支持度阈值作比较,保留大于或等于该阈值的项,得2项频繁项集 L 2 L_2 L2。
扫描所有事务, L 2 L_2 L2与 L 1 L_1 L1连接得候选3项集 C 3 C_3 C3,并计算每一项的支持度,如 P { a , b , c } = 项集 { a , b , c } 的支持度计数 所有事务个数 = 3 10 = 0.3 P\{a,b,c\}=\frac{项集\{a,b,c\}的支持度计数}{所有事务个数}=\frac{3}{10}=0.3 P{a,b,c}=所有事务个数项集{a,b,c}的支持度计数=103=0.3
接着是剪枝步, L 2 L_2 L2与 L 1 L_1 L1连接的所有项集为 { a , b , c } , { a , b , d } , { a , c , d } , { a , c , e } , { b , c , d } , { b , c , e } \{a,b,c\},\{a,b,d\},\{a,c,d\},\{a,c,e\},\{b,c,d\},\{b,c,e\} {a,b,c},{a,b,d},{a,c,d},{a,c,e},{b,c,d},{b,c,e}
根据Apriori算法,频繁项集的所有非空子集也必须是频繁项集,因为 { b , c } , { b , e } , { c , d } \{b,c\},\{b,e\},\{c,d\} {b,c},{b,e},{c,d}不包含在 b b b项频繁项集 L 2 L_2 L2中,即不是频繁项集,应剔除,最后的 C 3 C_3 C3中的项集只有 { a , b , c } \{a,b,c\} {a,b,c}和 { a , c , e } \{a,c,e\} {a,c,e}。
对 C 3 C_3 C3中各项集的支持度与预先设定的最小支持度阈值作比较,保留大于或等于该阈值的项,得3项频繁项集 L 3 L_3 L3; L 3 L_3 L3与 L 1 L_1 L1连接得候选4项集 C 4 C_4 C4,剪枝后得到的项集为空集。因此最后得到最大3项频繁项集 { a , b , c } \{a,b,c\} {a,b,c}和 { a , c , e } \{a,c,e\} {a,c,e}。
由以上过程可知 L 1 , L 2 , L 3 L_1,L_2,L_3 L1,L2,L3都是频繁项集, L 3 L_3 L3是最大频繁项集。
(2)过程二:由频繁集产生关联规则
自定义包apriori.py代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return result

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
尝试基于该例产生关联规则,在Python中实现上述Apriori算法的代码, 结果如图所示。
import pandas as pd
from apriori import * # 导入自行编写的apriori函数
# 读入数据
data = pd.read_excel('../data/menu_orders.xls', header=None)
data.head()
- 1
- 2
- 3
- 4
- 5
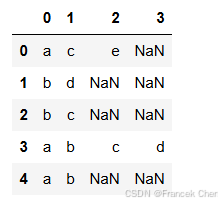
print('\n转换原始数据至0-1矩阵...')
ct = lambda x: pd.Series(1, index=x[pd.notnull(x)]) # 转换0-1矩阵的过渡函数
b = map(ct, data.to_numpy()) # 用map方式执行
data = pd.DataFrame(list(b)).fillna(0) # 实现矩阵转换,空值用0填充
print('\n转换完毕')
- 1
- 2
- 3
- 4
- 5

data.head()
- 1
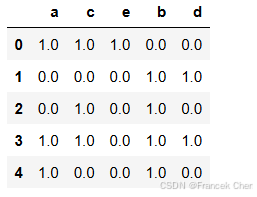
support = 0.2 # 最小支持度
confidence = 0.5 # 最小置信度
# 连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
ms = '---'
find_rule(data, support, confidence, ms).to_excel('../tmp/outputfile.xls', encoding='utf-8') # 保存结果
- 1
- 2
- 3
- 4
- 5
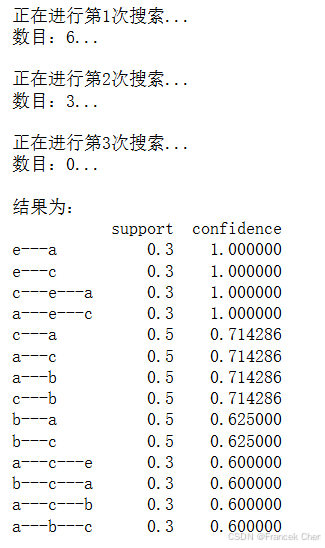
针对图中第一条输出结果进行解释:客户同时点菜品e和a的概率是30%,点了菜品e,再点菜品a的概率是100%。知道了这些,就可以对顾客进行智能推荐,增加销量的同时满足客户需求。
(三)FP-Growth算法
FP-Growth算法不同于Apriori算法生成候选项集再检查是否频繁的“产生-测试”方法,而是使用一种称为频繁模式树(FP-Tree,FP代表频繁模式,Frequent Pattern)的菜单紧凑数据结构组织数据,并直接从该结构中提取频繁项集。
1. FP-Growth算法的基本过程
相比于Apriori对每个潜在的频繁项集都需要扫描数据集判定是否满足支持度,FP-Growth算法只需要遍历两次数据集,因此它在大数据集上的速度显著优于Apriori。FP-Growth算法的基本运作步骤如下。
① 扫描数据,得到所有1项频繁一项集的计数。然后删除支持度低于阈值的项,将1项频繁项集放入项头表,并按照支持度降序排列。
② 读入排序后的数据集,插入FP树,插入时将项集按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表连接新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
③ 从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项的频繁项集。
④ 如果不限制频繁项集的项数,则返回步骤3所有的频繁项集,否则只返回满足项数要求的频繁项集。
2. FP-Growth算法原理
FP-Growth算法主要包含3个部分:扫描数据集建立项头表、基于项头表建立FP-tree和基于FP-tree挖掘频繁项集。
(1)建立项头表
要建立FP-tree首先需要建立项头表,建立项头表需要先对数据集进行一次扫描,得到所有1项频繁一项集的计数,将低于设定的支持度阈值的项过滤掉后,将1项频繁集放入项头表并按照项集的支持度进行降序排序。之后对数据集进行第二次扫描,从原始数据中剔除1项非频繁项集,并按照项集的支持度降序排序。
以一个含有10条数据的数据集为例,数据集中的数据如表所示。
| 序号 | 数据 |
|---|---|
| 1 | A,B,C,E,F,H |
| 2 | A,C,G |
| 3 | E,I |
| 4 | A,C,D,E,G |
| 5 | A,D,E,L |
| 6 | E,J |
| 7 | A,B,C,E,F,P |
| 8 | A,C,D |
| 9 | A,C,E,G,M |
| 10 | A,C,E,G,K |
对数据集进行扫描,支持度阈值设为20%,由于H,I,L,J,K,P,M都仅出现一次,小于设定的20%的支持度阈值,因此将不进入项头表。将1项频繁项集按降序排序后构建的项头表如表所示。
| 频繁项 | 计数 |
|---|---|
| A | 8 |
| E | 8 |
| C | 7 |
| G | 4 |
| D | 3 |
| B | 2 |
| F | 2 |
第二次扫描数据,将每条数据中的1项非频繁项集删去,并按照项集的支持度降序排列。如数据项“A,B,C,E,F,H”,其中“H“为1项非频繁项集,剔除后按项集的支持度降序排列后的数据项为“A,E,C,B,F”,得到排序后的数据集如表所示。
| 序号 | 数据 |
|---|---|
| 1 | A,E,C,B,F |
| 2 | A,C,G |
| 3 | E |
| 4 | A,E,C,G,D |
| 5 | A,E,D |
| 6 | E |
| 7 | A,E,C,B,F |
| 8 | A,C,D |
| 9 | A,E,C,G |
| 10 | A,E,C,G |
(2)建立FP-tree
构建项头表并对数据集排序后,就可以开始建立FP-tree。建立FP-tree时按顺序读入排序后的数据集,插入FP-tree中时按照排序的顺序插入,排序最为靠前的是父节点,之后的是子孙节点。如果出现共同的父节点,则对应父节点的计数增加1次。插入时如果有新节点加入树中,则将项头表中对应的节点通过节点链表链接接上新节点。直至所有的数据项都插入FP-tree后,FP-tree完成建立过程。
以建立项头表的数据集为例,构建FP-tree的过程如图所示。
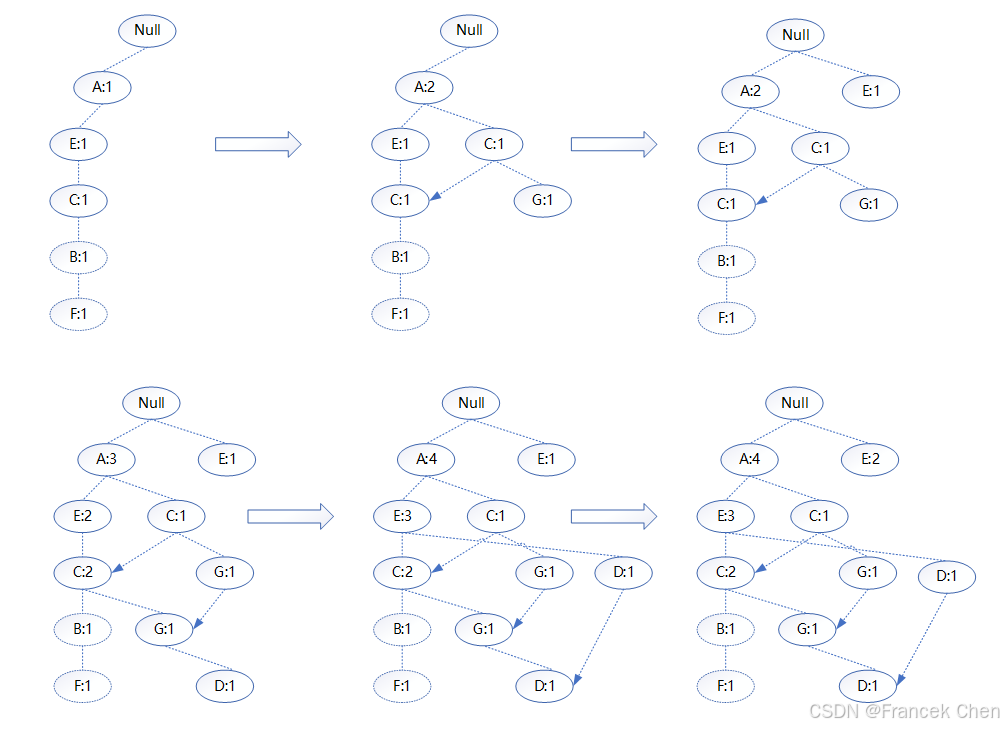
构建FP-tree具体步骤如下。
- 读入第一条数据“A,E,C,B,F”,此时FP-tree中没有节点,按顺序构成一条完整路径,每个节点的计数为1。
- 读入第二条数据“A,C,G”,在A节点处延伸一条新路径,并且A节点计数加1,其余节点计数为1。
- 读入第三条数据“E”,从根节点位置延伸一条新路径,计数为1。
- 读入第四条数据“A,E,C,G,D”,在C节点处延伸一条新路径,共用的“A,E,C”计数加1,新建的节点计数为1。
- 重复以上步骤直至整个FP-tree构建完成。
最终得到的FP-tree如图所示。
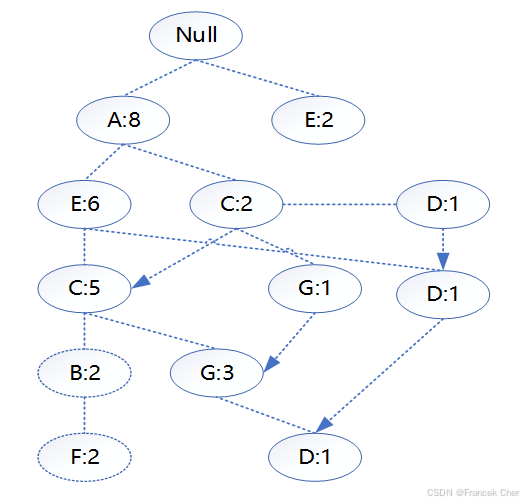
(3)挖掘频繁项集
在构建FP-tree、项头表和节点链表后,需要从项头表的底部项依次向上挖掘频繁项集。这需要找到项头表中对应于FP-tree的每一项的条件模式基。条件模式基是以要挖掘的节点作为叶子节点所对应的FP子树。
得到该FP子树后,将子树中每个节点的计数设置为叶子节点的计数,并删除计数低于最小支持度的节点。基于这个条件模式基就可以递归挖掘得到频繁项集了。
以构建F节点的条件模式基为例,F节点在FP-tree中只有一个子节点,因此只有一条路径{A:8,E:6,C:5,B:2,F:2},得到F节点的FP子树如图所示。
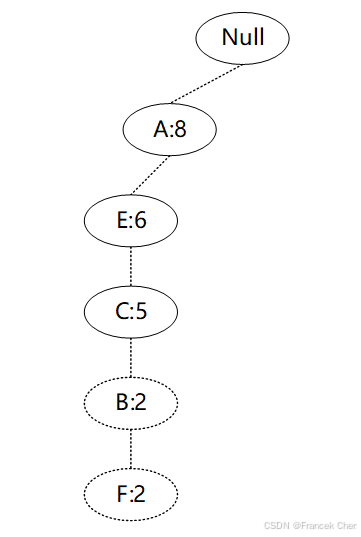
接着将所有的父节点的计数设置为子节点的计数,即FP子树变成{A:2,E:2,C:2,B:2,F:2}。通常条件模式基可以不写子节点,如图所示。
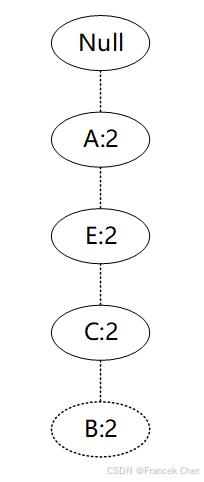
通过F节点的条件模式基可以得到F的频繁2项集为{A:2,F:2}、{E:2,F:2}、{C:2,F:2}、{B:2,F:2}。将2项集递归合并得到频繁3项集为{A:2,C:2,F:2}、{A:2,E:2,F:2}等等。最终递归得到最大的频繁项集为频繁5项集{A:2, E:2,C:2, B:2,F:2}。
获取B节点的频繁项集的过程与F节点类似,此处不再列出,需要特别提一下D节点。D节点在树中有三个子节点,得到D节点的FP子树如图所示。
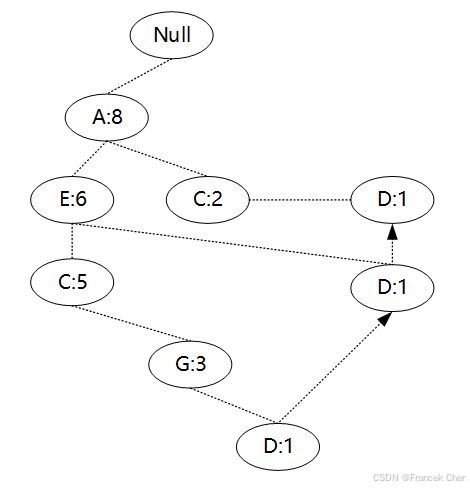
接着将所有的父节点计数设置为子节点的计数,即变成{A:3,E:2,C:2,G:1,D:1,D:1,D:1},由于G节点在子树中的支持度低于阈值,在去除低支持度节点并不包括子节点后D的条件模式基为{A:3,E:2,C:2}。通过D的条件模式基得到D的频繁2项集为{A:3,D:3},{E:2,D:2},{C:2,D:2}。
递归合并2项集,得到频繁3项集为{A:2,E:2,D:2},{A:2,C:2,D:2}。D节点对应的最大的频繁项集为频繁3项集。其余节点可以用类似的方法得出对应的频繁项集。
3. 使用FP-Growth算法实现新闻站点点击流频繁项集挖掘
使用FP-Growth算法挖掘匈牙利在线新闻门户的点击流数据kosarak.dat中的频繁项集,该数据有将近100万条记录,每一行包含某个用户浏览过的新闻报道。新闻报道被编码成整数,使用FP-growth算法挖掘其中的频繁项集,查看哪些新闻ID被用户大量浏览。
自定义包fpGrowth.py代码如下:
# -*- coding: utf-8 -*-
class treeNode:
"""
FP-tree树类
"""
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None # 用于链接相似的元素项
self.parent = parentNode # 指向当前节点的父节点
self.children = {} # 用于存放节点的子节点
def inc(self,numOccur):
self.count += numOccur
# 以文本的形式显示树
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
# 构建FP-tree
def createTree(dataSet, minSup=1):
headerTable = {}
for trans in dataSet: # 第一次遍历:统计各个数据的频繁度
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 用项头表统计各个类别的出现的次数,计算频繁量:项头表[类别]=出现次数
for k in list(headerTable): # 删除未达到最小频繁度的数据
if headerTable[k] < minSup:
del (headerTable[k])
freqItemSet = set(headerTable.keys()) # 保存达到要求的数据
if len(freqItemSet) == 0:
return None, None # 若达到要求的数目为0
for k in headerTable: # 遍历项头表
headerTable[k] = [headerTable[k], None] # 保存计数值及指向每种类型第一个元素项的指针
retTree = treeNode('Null Set', 1, None) # 初始化tree
for tranSet, count in dataSet.items(): # 第二次遍历
localD = {}
for item in tranSet:
if item in freqItemSet: # 只对频繁项集进行排序
localD[item] = headerTable[item][0]
# 使用排序后的频率项集对树进行填充
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable # 返回构建的树和项头表
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # 检查是否存在该节点
inTree.children[items[0]].inc(count) # 存在则计数增加
else: # 不存在则将新建该节点
inTree.children[items[0]] = treeNode(items[0], count, inTree) # 创建一个新节点
if headerTable[items[0]][1] == None: # 若原来不存在该类别,更新项头表
headerTable[items[0]][1] = inTree.children[items[0]] # 更新指向
else: # 更新指向
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # 如果仍有未分配完的树,继续迭代
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
# 节点链接指向树中该元素项的每一个实例。
# 从项头表的 nodeLink 开始,一直沿着nodeLink直到到达链表末尾
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
# 将数据从列表转换到字典的类型
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
# 从FP树中发现频繁项集
def ascendTree(leafNode, prefixPath): # 递归上溯整棵树
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, treeNode): # 参数:指针,节点
condPats = {}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath) # 寻找当前非空节点的前缀
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count # 将条件模式基添加到字典中
treeNode = treeNode.nodeLink
return condPats
# 递归查找频繁项集
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
# 头指针表中的元素项按照频繁度排序,从小到大
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: str(p[1]))]
for basePat in bigL: # 从底层开始
# 加入频繁项列表
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
print ('finalFrequent Item: ',newFreqSet)
freqItemList.append(newFreqSet)
# 递归调用函数来创建基
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
print ('condPattBases :',basePat, condPattBases)
# 构建条件模式Tree
myCondTree, myHead = createTree(condPattBases, minSup)
# 将创建的条件基作为新的数据集添加到fp-tree
print ('head from conditional tree: ', myHead)
if myHead != None: # 递归
print ('conditional tree for: ',newFreqSet)
myCondTree.disp(1)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
# 主函数封装
def fpGrowth(dataSet, minSup=3):
initSet = createInitSet(dataSet)
myFPtree, myHeaderTab = createTree(initSet, minSup)
freqItems = []
mineTree(myFPtree, myHeaderTab, minSup, set([]), freqItems)
return freqItems
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
在Python中实现FP-Growth算法挖掘新闻门户的点击流数据的代码,结果如下。
import fpGrowth
# 读取数据并转换格式
newsdata = [line.split() for line in open('../data/kosarak.dat').readlines()]
indataset = fpGrowth.createInitSet(newsdata)
# 构建树寻找其中浏览次数在5万次以上的新闻
news_fptree, news_headertab = fpGrowth.createTree(indataset, 50000)
# 创建空列表用于保持频繁项集
newslist = []
fpGrowth.mineTree(news_fptree, news_headertab, 50000, set([]), newslist)
# 查看结果
print('浏览次数在5万次以上的新闻报导集合个数:', len(newslist))
print('浏览次数在5万次以上的新闻:\n', newslist)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
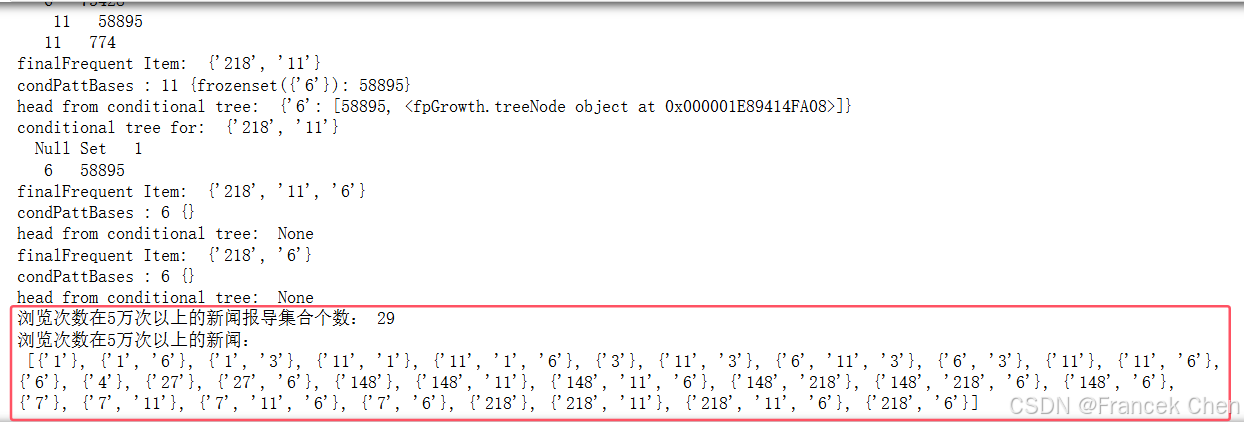
可以得到该网站上浏览次数超过5万次的新闻集合的个数为29个。
四、基于协同过滤的智能推荐
常见的协同过滤推荐技术主要分为两大类。
- 基于用户的协同过滤推荐。
- 基于物品的协同过滤推荐。
(一)基于用户的协同过滤
基于用户的协同过滤的基本思想相当简单,基于用户对物品的偏好找到相邻用户,然后将邻居用户喜欢的推荐给当前用户。在计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到K邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。如右图给出了一个例子,对于用户A,根据用户的历史偏好,这里只计算得到一个邻居-用户C,可以将用户C喜欢的物品D推荐给用户A。

1. 算法原理
实现基于用户的协同过滤算法第一个重要的步骤就是计算用户之间的相似度。而计算相似度,建立相关系数矩阵目前主要分为以下几种方法。
(1)皮尔逊相关系数
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在[-1,+1]区间内。皮尔森相关系数等于两个变量的协方差除于两个变量的标准差,计算公式如下。 s ( X , Y ) = C o v ( X , Y ) σ X σ Y s(X,Y)=\frac{\mathrm{Cov(X,Y)}}{\sigma_X\sigma_Y} s(X,Y)=σXσYCov(X,Y)
由于皮尔逊相关系数描述的是两组数据变化移动的趋势,所以在基于用户的协同过滤系统中经常被使用。描述用户购买或评分变化的趋势,若趋势相近,则皮尔逊系数趋近于1,即认为用户相似。
(2)基于欧几里得距离的相似度
欧几里得距离计算相似度是所有相似度计算里面最简单、最易理解的方法,它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到坐标系上,并计算这些人彼此之间的直线距离 ∑ ( X i − Y i ) 2 \sqrt{\sum{(X_i-Y_i)^2}} ∑(Xi−Yi)2。计算得到的欧几里得距离是一个大于0的数,为了使其更能体现用户之间的相似度,可以把它规约到(0,1]区间内,最终得到的计算公式如下。 s ( X , Y ) = 1 1 + ∑ ( X i − Y i ) 2 s(X,Y)=\frac{1}{1+\sqrt{\sum{(X_i-Y_i)^2}}} s(X,Y)=1+∑(Xi−Yi)21
只要至少有一个共同评分项,即可用欧几里得距离计算相似度;如果没有共同评分项,那么欧几里得距离也就失去了作用,这也意味着这两个用户根本不相似。
(3)余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小,如右图所示。余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上,计算公式如下。 s ( X , Y ) = cos θ = x ⃗ ⋅ y ⃗ ∥ x ∥ ⋅ ∥ y ∥ s(X,Y)=\cos\theta=\frac{\vec{x}\cdot\vec{y}}{\Vert x\Vert\cdot\Vert y\Vert} s(X,Y)=cosθ=∥x∥⋅∥y∥x⋅y
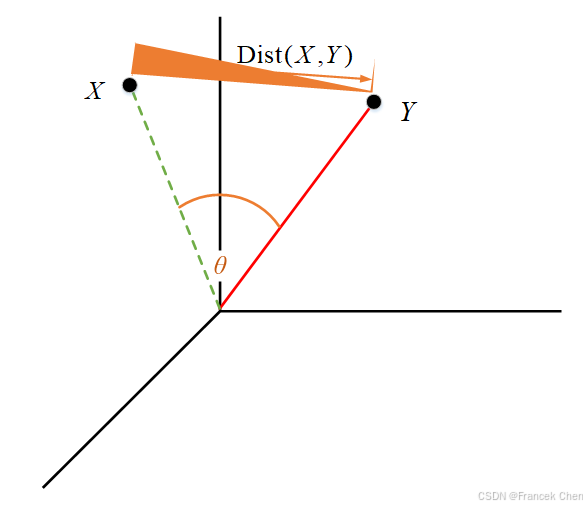
从上图可以看出,距离度量衡量的是空间各点间的绝对距离,跟各个点所在的位置坐标(即个体特征维度的数值)直接相关;而余弦相似度衡量的是空间向量的夹角,更多的是体现在方向上的差异,而不是位置。如果保持 X X X点的位置不变, Y Y Y点朝原方向远离坐标轴原点,那么这个时候余弦相似度 cos θ \cos\theta cosθ是保持不变的,因为夹角不变,而 X X X、 Y Y Y两点的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
(4)预测评分
基于用户的协同过滤算法,另一个重要的步骤是计算用户 u u u对未评分商品的预测分值。首先根据上一步中的相似度计算,寻找用户 u u u的邻居集 N ∈ U N\in U N∈U,其中 N N N表示邻居集, U U U表示用户集。然后结合用户评分数据集,预测用户 u u u对项 i i i的评分,计算公式如下: p u , i = r ˉ + ∑ u ′ ⊂ N s ( u − u ′ ) ( r u ′ , i − r ˉ u ′ ) ∑ u ′ ⊂ N ∣ s ( u − u ′ ) ∣ p_{u,i}=\bar{r}+\frac{\sum\limits_{u'\subset N}s(u-u')(r_{u',i}-\bar{r}_{u'})}{\sqrt{\sum\limits_{u'\subset N}|s(u-u')|}} pu,i=rˉ+u′⊂N∑∣s(u−u′)∣u′⊂N∑s(u−u′)(ru′,i−rˉu′)
其中, s ( u − u ′ ) s(u-u') s(u−u′)表示用户 u u u和用户 u ′ u' u′的相似度。最后,基于对未评分商品的预测分值排序,得到推荐商品列表。
2. 基于用户的个性化的电影推荐
通过个性化的电影推荐的实例演示基于用户的协同过滤算法在Python中的实现。现今影视已经成为大众喜爱的休闲娱乐的方式之一,合理的个性化电影推荐一方面能够促进电影行业的发展,另一方面也可以让用户在数量众多的电影中迅速得到自己想要的电影,做到两全齐美。甚至更近一步,可以明确市场走向,对后续电影的类型导向等起到重要作用。
MovieLens数据集记录了943个用户对1682部电影的共100000个评分,每个用户至少对20部电影进行了评分。脱敏后的部分电影评分数据如下表所示。
| 用户ID | 电影ID | 电影评分 | 时间标签 |
|---|---|---|---|
| 1 | 1 | 5 | 874965758 |
| 1 | 2 | 3 | 876893171 |
| 1 | 3 | 4 | 878542960 |
| 1 | 4 | 3 | 876893119 |
| 1 | 5 | 3 | 889751712 |
| 1 | 6 | 4 | 875071561 |
| 1 | 7 | 1 | 875072484 |
| … | … | … | … |
自定义包recommender.py代码如下:
import numpy as np
import pandas as pd
import math
def prediction(df,userdf,Nn=15):#Nn邻居个数
corr=df.corr();
rats=userdf.copy()
for itemid in userdf.columns:
dfnull=userdf.loc[:,itemid][userdf.loc[:,itemid].isnull()]
itemv=df.loc[:,itemid].mean()#评价平均值
for usrid in dfnull.index:
nft=(df.loc[usrid]).notnull()
#获取该用户评过分的物品中最相似邻居物品列表,且取其中Nn个,如果不够Nn个则全取
nlist=df.loc[usrid][nft]
nlist=nlist[(corr.loc[itemid,nlist.index][corr.loc[itemid,nlist.index].notnull()].sort_values(ascending=False)).index]
if(Nn<=len(nlist)):
nlist=(df.loc[usrid][nft])[:Nn]
else:
nlist=df.loc[usrid][nft][:len(nlist)]
nratsum=0
corsum=0
if(0!=nlist.size):
nv=df.loc[:,nlist.index].mean()#邻居评价平均值
for index in nlist.index:
ncor=corr.loc[itemid,index]
nratsum+=ncor*(df.loc[usrid][index]-nv[index])
corsum+=abs(ncor)
if(corsum!=0):
rats.at[usrid,itemid]= itemv + nratsum/corsum
else:
rats.at[usrid,itemid]= itemv
else:
rats.at[usrid,itemid]= None
return rats
def recomm(df,userdf,Nn=15,TopN=3):
ratings=prediction(df,userdf,Nn)#获取预测评分
recomm=[]#存放推荐结果
for usrid in userdf.index:
#获取按NA值获取未评分项
ratft=userdf.loc[usrid].isnull()
ratnull=ratings.loc[usrid][ratft]
#对预测评分进行排序
if(len(ratnull)>=TopN):
sortlist=(ratnull.sort_values(ascending=False)).index[:TopN]
else:
sortlist=ratnull.sort_values(ascending=False).index[:len(ratnull)]
recomm.append(sortlist)
return ratings,recomm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
在Python中实现基于用户的协同过滤算法进行个性化电影推荐。将原始的事务性数据导入Python中,因为原始数据无字段名,所以首先需要对相应的字段进行重命名,再运行基于用户的协同过滤算法。得到用户预测评分数据和用户推荐列表数据,如下所示。
# 使用基于UBCF算法对电影进行推荐
import pandas as pd
from recommender import recomm # 加载自编推荐函数
# 读入数据
traindata = pd.read_csv('../data/u1.base', sep='\t', header=None, index_col=None)
testdata = pd.read_csv('../data/u1.test', sep='\t', header=None, index_col=None)
# 删除时间标签列
traindata.drop(3, axis=1, inplace=True)
testdata.drop(3, axis=1, inplace=True)
# 行与列重新命名
traindata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
testdata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
traindf = traindata.pivot(index='userid', columns='movid', values='rat')
testdf = testdata.pivot(index='userid', columns='movid', values='rat')
traindf.rename(index={i: 'usr%d' % (i) for i in traindf.index}, inplace=True)
traindf.rename(columns={i: 'mov%d' % (i) for i in traindf.columns}, inplace=True)
testdf.rename(index={i: 'usr%d' % (i) for i in testdf.index}, inplace=True)
testdf.rename(columns={i: 'mov%d' % (i) for i in testdf.columns}, inplace=True)
userdf = traindf.loc[testdf.index]
# 获取预测评分和推荐列表
trainrats, trainrecomm = recomm(traindf, userdf)
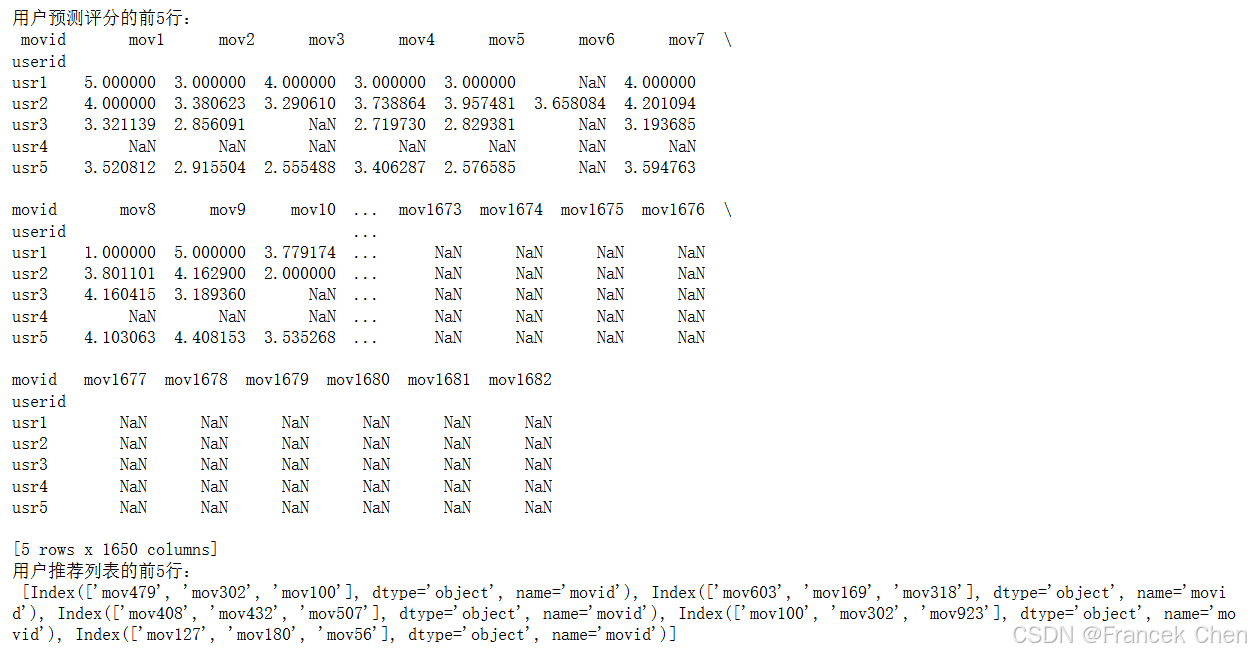
print('用户预测评分的前5行:\n', trainrats.head())
# 保存预测的评分
trainrats.to_csv('../tmp/movie_comm.csv', index=False, encoding='utf-8')
print('用户推荐列表的前5行:\n', trainrecomm[:5])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
(二)基于物品的协同过滤
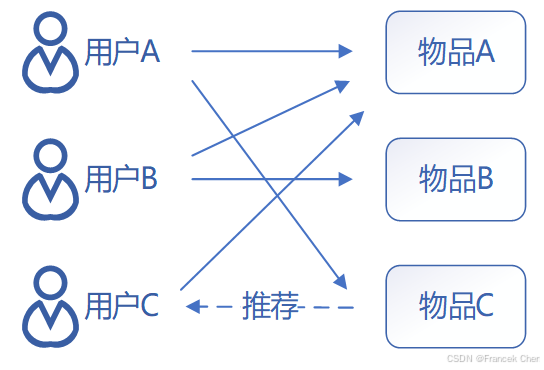
基于物品的协同过滤的原理和基于用户的协同过滤类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,再根据用户的历史偏好,推荐相似的物品给用户。从计算的角度看,是将所有用户对某个物品的偏好作为一个向量计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户都喜欢物品C,得出物品A和物品C比较相似,而用户C喜欢物品A,可以推断出用户C可能也喜欢物品C,如图所示。
1. 算法过程
根据协同过滤的处理过程可知,基于物品的协同过滤算法(简称ItemCF算法)主要分为两个步骤。
- 计算物品之间的相似度。
- 根据物品的相似度和用户的历史行为为用户生成推荐列表。
其中关于物品相似度计算的方法有夹角余弦、杰卡德(Jaccard)相似系数和相关系数等。将用户对某一个物品的喜好或评分作为一个向量,例如,所有用户对物品1的评分或喜好程度表示为 A 1 = ( x 11 , x 21 , x 31 , ⋯ , x n 1 ) A_1=(x_{11},x_{21},x_{31},\cdots,x_{n1}) A1=(x11,x21,x31,⋯,xn1),所有用户对物品 M M M的评分或喜好程度表示为 A M = ( x 1 m , x 2 m , x 3 m , ⋯ , x n m ) A_M=(x_{1m},x_{2m},x_{3m},\cdots,x_{nm}) AM=(x1m,x2m,x3m,⋯,xnm),其中 m m m为物品, n n n为用户数。采用物品相似度几种计算方法计算两个物品之间的相似度,其计算公式如下表所示。
| 方法 | 公式 | 说明 |
|---|---|---|
| 夹角余弦 | s i m l m = ∑ k = 1 n x k 1 x k m ∑ k = 1 n x k 1 2 ∑ k = 1 n x k m 2 \begin{aligned}\mathrm{sim}_{lm}=\frac{\sum_{k=1}^{n}x_{k1}x_{km}}{\sqrt{\sum_{k=1}^{n}x_{k1}^2}\sqrt{\sum_{k=1}^{n}x_{km}^2}}\end{aligned} simlm=∑k=1nxk12∑k=1nxkm2∑k=1nxk1xkm | k k k表示用户,取值范围为[-1,1]区间内,当余弦值接近±1,表明两个向量有较强的相似性。当余弦值为0时表示不相关 |
| 杰卡德相似系数 | J ( A L , A M ) = ∣ A L ∩ A M ∣ ∣ A L ∪ A M ∣ \begin{aligned}J(A_L,A_M)=\frac{\lvert A_L\cap A_M\rvert}{\lvert A_L\cup A_M\rvert}\end{aligned} J(AL,AM)=∣AL∪AM∣∣AL∩AM∣ | 分母 A L ∪ A M A_L \cup A_M AL∪AM表示喜欢物品 L L L与喜欢物品 M M M的用户总数,分子 A L ∩ A M A_L \cap A_M AL∩AM表示同时喜欢物品 L L L和物品 M M M的用户数 |
| 相关系数 | s i m l m = ∑ k = 1 n ( x k 1 − A ‾ L ) ( x k m − A ‾ M ) ∑ k = 1 n ( x k 1 − A ‾ L ) 2 ∑ k = 1 n ( x k m − A ‾ M ) 2 \begin{aligned}\mathrm{sim}_{lm}=\frac{\sum_{k=1}^{n}(x_{k1}-\overline{A}_L)(x_{km}-\overline{A}_M)}{\sqrt{\sum_{k=1}^{n}(x_{k1}-\overline{A}_L)^2}\sqrt{\sum_{k=1}^{n}(x_{km}-\overline{A}_M)^2}}\end{aligned} simlm=∑k=1n(xk1−AL)2∑k=1n(xkm−AM)2∑k=1n(xk1−AL)(xkm−AM) | 相关系数的取值范围固定在[-1,1]区间内。相关系数的绝对值越大,则表明两者相关度越高 |
计算各个物品之间的相似度后,即可构成一个物品之间的相似度矩阵,如下表所示。通过相似度矩阵,推荐算法会为用户推荐与用户偏好的物品最相似的 K K K个的物品。
| 物品 | A | B | C | D |
|---|---|---|---|---|
| A | 1 | 0.763 | 0.251 | 0 |
| B | 0.763 | 1 | 0.134 | 0.529 |
| C | 0.251 | 0.134 | 1 | 0.033 |
| D | 0 | 0.529 | 0.033 | 1 |
下式度量了推荐算法中用户对所有物品的感兴趣程度。其中 R R R代表了用户对物品的兴趣, s i m \mathrm{sim} sim代表了所有物品之间的相似度, P P P为用户对物品感兴趣的程度。 P = s i m × R P=\mathrm{sim}\times R P=sim×R
推荐系统是根据物品的相似度以及用户的历史行为对用户的兴趣度进行预测并推荐,在评价模型的时候一般是将数据集划分成训练集和测试集两部分。模型通过在训练集的数据上进行训练学习得到推荐模型,然后在测试集数据上进行模型预测,最终统计出相应的评测指标评价模型预测效果的好与坏。
模型的评测采用的方法是交叉验证法。交叉验证法即将用户行为数据集按照均匀分布随机分成M份,挑选一份作为测试集,将剩下的M-1份作为训练集。在训练集上建立模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。最后将M次实验测出的评测指标的平均值作为最终的评测指标。
构建基于物品的协同过滤推荐模型的流程如图所示。
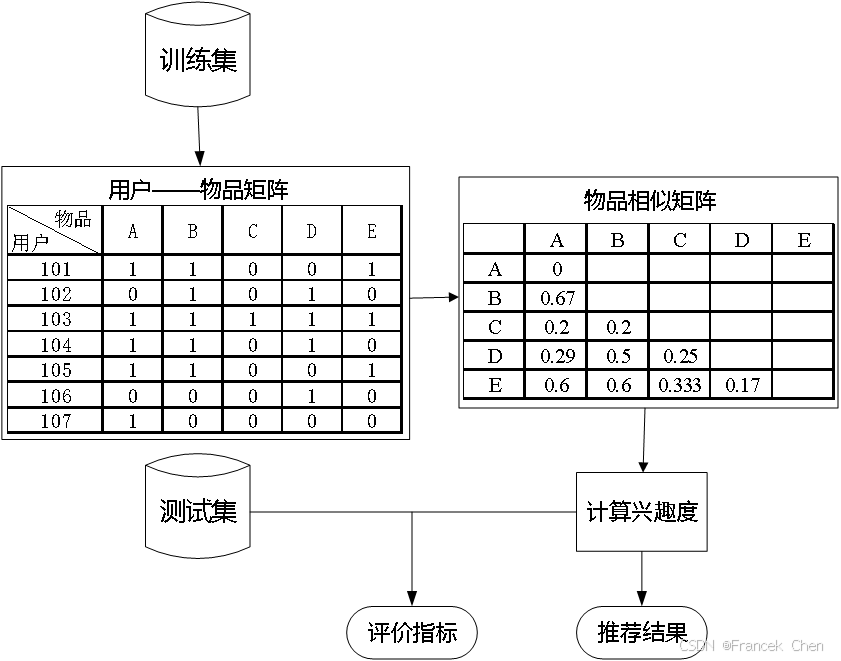
其中训练集与测试集是通过交叉验证的方法划分后的数据集。通过协同过滤算法的原理可知,在建立推荐系统时,建模的数据量越大,越能消除数据中的随机性,得到的推荐结果越好。算法的弊端在于数据量越大,模型建立和模型计算耗时越久。
2. 基于物品的个性化电影推荐
同样使用MovieLens数据集,将原始数据导入Python后使用基于物品的协同过滤算法进行个性化电影推荐,结果如图所示。
import pandas as pd
# 读入数据
traindata = pd.read_csv('../data/u1.base', sep='\t', header=None, index_col=None)
testdata = pd.read_csv('../data/u1.test', sep='\t', header=None, index_col=None)
# 删除时间标签列
traindata.drop(3, axis=1, inplace=True)
testdata.drop(3, axis=1, inplace=True)
# 行与列重新命名
traindata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
testdata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
# 构建训练集数据
user_tr = traindata.iloc[:, 0] # 训练集用户id
mov_tr = traindata.iloc[:, 1] # 训练集电影id
user_tr = list(set(user_tr)) # 去重处理
mov_tr = list(set(mov_tr)) # 去重处理
print('训练集电影数:', len(mov_tr))
# 利用训练集数据构建模型
ui_matrix_tr = pd.DataFrame(0, index=user_tr, columns=mov_tr)
# 求用户-物品矩阵
for i in traindata.index:
ui_matrix_tr.loc[traindata.loc[i, 'userid'], traindata.loc[i, 'movid']] = 1
print('训练集用户观影次数:', sum(ui_matrix_tr.sum(axis=1)))
# 求物品相似度矩阵(因计算量较大,需要耗费的时间较久)
item_matrix_tr = pd.DataFrame(0, index=mov_tr, columns=mov_tr)
for i in item_matrix_tr.index:
for j in item_matrix_tr.index:
a = sum(ui_matrix_tr.loc[:, [i, j]].sum(axis=1) == 2)
b = sum(ui_matrix_tr.loc[:, [i, j]].sum(axis=1) != 0)
item_matrix_tr.loc[i, j] = a / b
# 将物品相似度矩阵对角线处理为零
for i in item_matrix_tr.index:
item_matrix_tr.loc[i, i] = 0
# 利用测试集数据对模型评价
user_te = testdata.iloc[:, 0]
mov_te = testdata.iloc[:, 1]
user_te = list(set(user_te))
mov_te = list(set(mov_te))
# 测试集数据用户物品矩阵
ui_matrix_te = pd.DataFrame(0, index=user_te, columns=mov_te)
for i in testdata.index:
ui_matrix_te.loc[testdata.loc[i, 'userid'], testdata.loc[i, 'movid']] = 1
# 对测试集用户进行推荐
res = pd.DataFrame('NaN', index=testdata.index, columns=['User', '已观看电影', '推荐电影', 'T/F'])
res.loc[:, 'User'] = list(testdata.iloc[:, 0])
res.loc[:, '已观看电影'] = list(testdata.iloc[:, 1])
# 开始推荐
for i in res.index:
if res.loc[i, '已观看电影'] in list(item_matrix_tr.index):
res.loc[i, '推荐电影'] = item_matrix_tr.loc[res.loc[i, '已观看电影'], :].argmax()
if res.loc[i, '推荐电影'] in mov_te:
res.loc[i, 'T/F'] = ui_matrix_te.loc[res.loc[i, 'User'], res.loc[i, '推荐电影']] == 1
else:
res.loc[i, 'T/F'] = False
# 保存推荐结果
res.to_csv('../tmp/res_mov.csv', index=False, encoding='utf8')
print('推荐结果前5行: \n', res.head())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
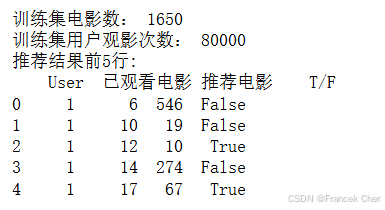
通过基于物品的协同过滤算法构建的推荐系统,得到针对用户每次观影记录的用户观影推荐,但是推荐结果可能存在NaN的情况。这种情况是由于在目前的数据集中,观看该电影的只有单独一个用户,使用协同过滤算法计算该电影与其他电影的相似度为0,所以出现了无法推荐的情况。
小结
本文首先介绍了智能推荐的概念、应用、评价指标。智能推荐系统能帮助用户找到自己喜爱的物品,同时也能帮助厂商和网站推广产品。智能推荐的应用范围涵盖多个领域,包括电子商务、视频网站、音乐、社交网络等。评价标准可分为3个方面,即离线实验、用户调查和在线实验。
接着介绍了智能推荐几种常见的智能推荐算法,包括关联规则和协同过滤等,其中关联规则可以挖掘出物品间的关联关系,依据关联关系的强弱为用户推荐,常见的关联规则算法有Apriori和FP-Growth。
常见的协同过滤推荐技术主要分为两大类,基于用户的协同过滤推荐和基于物品的协同过滤推荐。基于用户的智能推荐侧重于给用户推荐相似用户喜好的物品,而基于物品的智能推荐更侧重于用户本身的历史浏览记录。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/2361df48c692
提取码:umgL

 微信名片
微信名片

评论记录:
回复评论: